2019年12月17日
memsetのベンチマーク(AArch64, Cortex-A72編)
目次: ベンチマーク
(参考)コード一式はGitHubに置きました(GitHubへのリンク)
先日Ryzen 7 2700なx86_64マシンでmemsetの性能を計測(2019年12月14日の日記参照)しました。同様の計測をAArch64でもやってみました。環境はRK3399 Cotex-A72 1.8GHzです。メモリはおそらくLPDDR3-1600のはず、OSはDebian GNU/Linux 10.2 busterです。
リファレンスとするのは前回同様、システムにインストールされているglibc-2.28のmemset関数(アセンブラ版)です。大抵の場合、この関数が最速ですね。
ざっとglibc-2.28の実装を見たところ、x86_64向けは各種SIMD向けに最適化されたアセンブラコード(glibc/sysdeps/x86_64/multiarch/memset-avx2-unaligned-erms.Sなど)が使われて、aarch64向けは汎用的なアセンブラコード(glibc/sysdeps/aarch64/memset.S)が使われるようです。
まずは最適化オプションO3とO2の差から見てみようと思います。
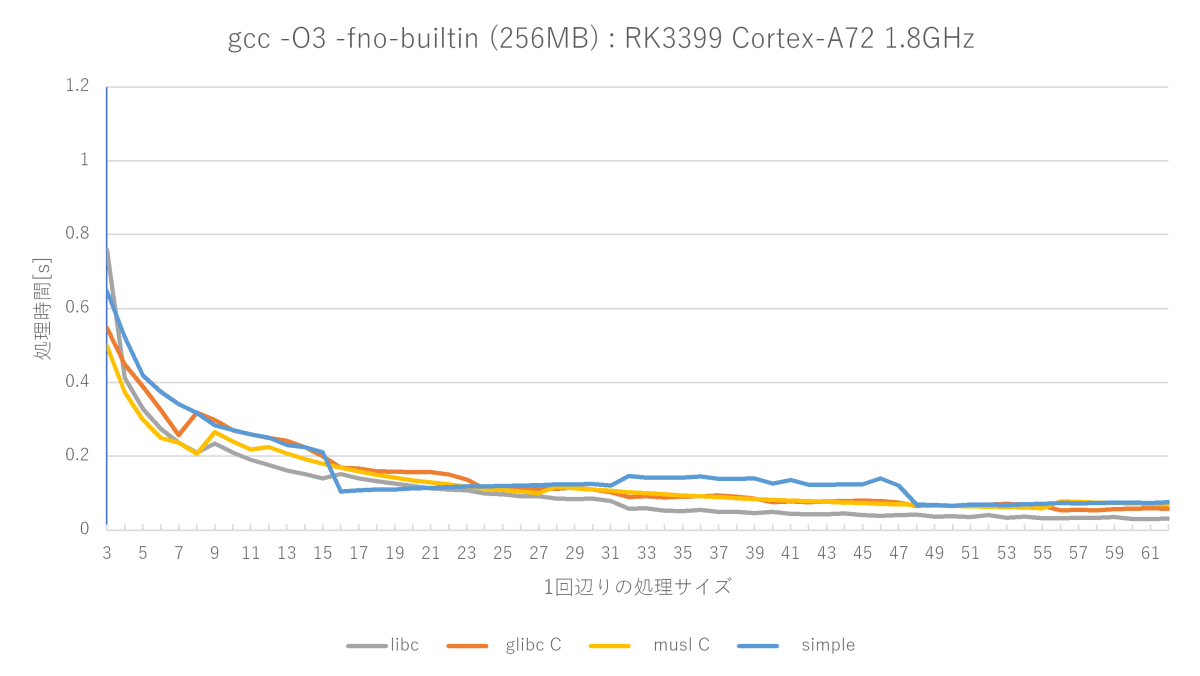
gcc -O3 -fno-builtinの測定結果(Cortex-A72編)
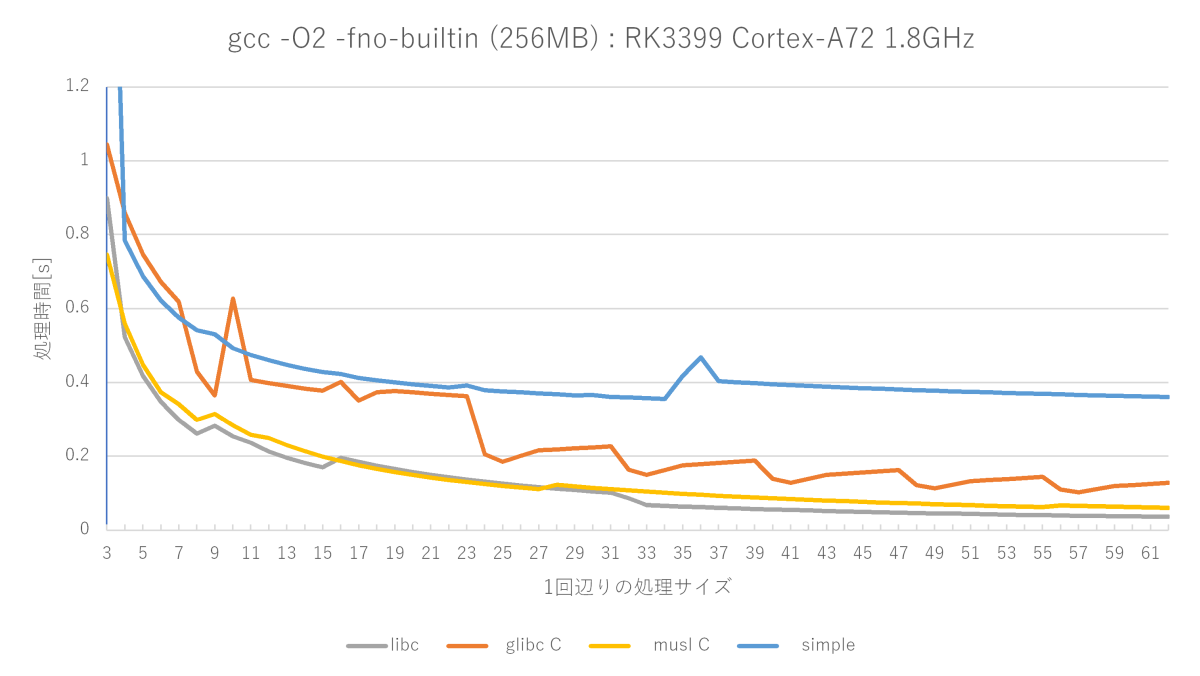
gcc -O2 -fno-builtinの測定結果(Cortex-A72編)
やはりO3の最適化による速度向上はさすがとしか言えません。x86_64ではあまり振るわなかったmusl memset関数が非常に優秀で、libcのmemsetに並ぶ勢いです。
AArch64のNEONを使ったベクトル最適化
前回はベクトル最適化 -ftree-vectorizeオプションを使うとほぼO3の性能に追い付きましたが、AArch64ではどうなるでしょう?
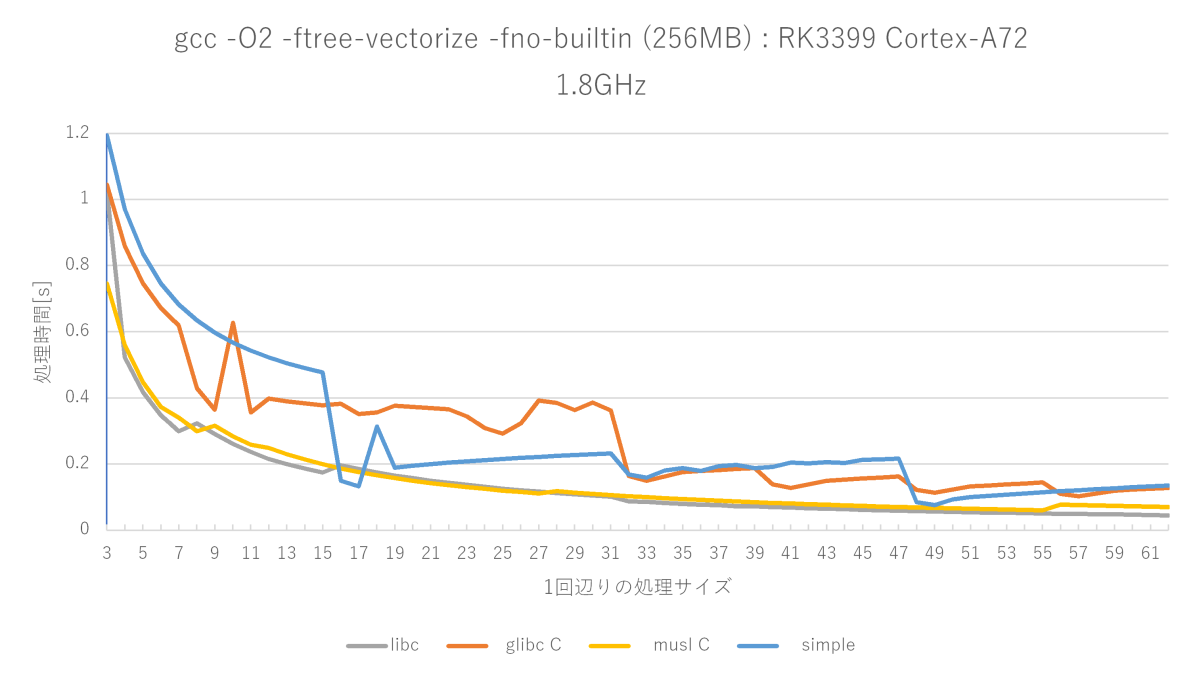
gcc -O2 -ftree-vectorize -fno-builtinの測定結果(Cortex-A72編)
ベクトル最適化を有効にするとNEONの128bitストア命令が使われるようになります。
O2と比較すると確かに性能向上していますが、x86_64ほどの威力は発揮しません。
メモ: 技術系の話はFacebookから転記しておくことにした。大幅に加筆。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
| < | 2019 | > | ||||
| << | < | 12 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | - | - | - | - |
最近のコメント20件
-
 14年6月13日
14年6月13日
2048player...さん (09/26 01:04)
「最後に、この式を出すのに紙4枚(A4)も...」 -
14年6月13日
2048playerさん (09/26 01:00)
「今のところ最も簡略化した式です。\n--...」 -
14年6月13日
2048playerさん (09/16 01:00)
「返信ありがとうございます。\nコメントが...」 -
14年6月13日
すずきさん (09/12 21:19)
「コメントありがとうございます。同じ結果に...」 -
14年6月13日
2048playerさん (09/08 17:30)
「私も2048の最高スコアを求めたのですが...」 -
14年6月13日
2048さん (09/08 17:16)
「私も2048の最高スコアを求めたのですが...」 -
14年6月13日
2048playerさん (09/08 16:10)
「私も2048の最高スコアを求めたのですが...」 -
02年8月4日
lxbfYeaaさん (07/12 10:11)
「555」 -
24年6月17日
すずきさん (06/23 00:12)
「ありがとうございます。バルコニーではない...」 -
24年6月17日
hdkさん (06/22 22:08)
「GPSの最初の同期を取る時は見晴らしのい...」 -
24年5月16日
すずきさん (05/21 11:41)
「あー、確かにdpkg-reconfigu...」 -
24年5月16日
hdkさん (05/21 08:55)
「システム全体のlocale設定はDebi...」 -
24年5月17日
すずきさん (05/20 13:16)
「そうですねえ、普通はStandardなの...」 -
24年5月17日
hdkさん (05/19 07:45)
「なるほど、そういうことなんですね。Exc...」 -
24年5月17日
すずきさん (05/19 03:41)
「Standardだと下記の設定になってい...」 -
24年5月17日
hdkさん (05/18 22:16)
「ドメインを変えたせいで別サイト扱いになっ...」 -
24年4月22日
hdkさん (04/24 08:36)
「うちのHHFZ4310は15年突破しまし...」 -
24年4月22日
すずきさん (04/24 00:37)
「ちゃんと数えてないですけど蛍光管が10年...」 -
24年4月22日
hdkさん (04/23 20:52)
「おお... うちのHHFZ4310より後...」 -
20年6月19日
すずきさん (04/06 22:54)
「ディレクトリを予め作成しておけば良いです...」
最近の記事3件
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
