2014年5月30日
自作エミュレータ - ワード幅とハーフワード読み出し
目次: Linux
RISC CPUにはワード幅での読み書きしかできないアーキテクチャがありますが、より狭いハーフワードやバイトへのアクセスってどうしているのでしょう?
単純に考えると、ひとまず近しいアドレスからワード幅で読み出して、しかるべきシフト演算を行うことで、目的のハーフワードやバイトデータを得ていそうです。
例えば、ワード幅64bits、読みたいデータ幅16bits、アクセス先のアドレスが0x12として考えてみます。
まず、データバスにはアドレス0x12ではアクセスできませんので、ひとまず0x12を超えない最大の8の倍数(64bits = 8bytes)であるアドレス0x10から64bitsを読み出します。
このときバスから読み出したデータが0x1234_5678_0246_8aceだとして、バスから読み出したデータを読みたいデータ幅(= 16bits)ごとに分割し、符号ビットから近い順から並べると、
0x1234:
0x5678:
0x0246:
0x8ace:
となります。
リトルエンディアンシステムの場合、データの上位から、アドレス+6、アドレス+4、アドレス+2、アドレスそのもの、に対応しますので、
0x1234: アドレス+6 = 0x16
0x5678: アドレス+4 = 0x14
0x0246: アドレス+2 = 0x12
0x8ace: アドレスそのもの = 0x10
と対応します。
従って目的のアドレス0x12にあるデータは0x0246であることがわかり、バスから読み出したデータをシフトすべき量は16bitsであることがわかります。
同様にアドレス0x14ならばデータは0x5678となり、シフトすべき量は32bitsです。
コードでどうぞ
このような処理をいちいち考えていると面倒で死にそうなので、コードで書いてみることにしました。
バスから読んだデータから対応するアドレスのデータを得る関数(リトルエンディアン)
public static long ADDR_MASK_64 = ~0x7L;
public static long ADDR_MASK_32 = ~0x3L;
public static long ADDR_MASK_16 = ~0x1L;
public static long ADDR_MASK_8 = ~0x0L;
/**
* @param dataLenデータ幅
* @returnアドレスマスク
*/
public long getAddressMask(int dataLen) {
switch (dataLen) {
case 64:
return ADDR_MASK_64;
case 32:
return ADDR_MASK_32;
case 16:
return ADDR_MASK_16;
case 8:
return ADDR_MASK_8;
default:
throw new IllegalArgumentException("Data length" +
String.format("(0x%08x) is not supported.", dataLen));
}
}
/*
* @param addr データのアドレス
* @param data バスから読んだデータ
* @param busLen データバス幅
* @param dataLen データ幅
* @return addrにあるデータ
*/
public long readMasked(long addr, long data, int busLen, int dataLen) {
long busMask = getAddressMask(busLen);
long dataMask = getAddressMask(dataLen);
int sh = (int)(addr & ~busMask & dataMask) * 8;
return data >> sh;
}
ふっざけんなー!意味がわからんわー!!と叫んでいる半年後の自分が見えたので、併せて解説も書いておきます。
バスから読み出したデータをシフトする量を求める部分がaddr & ~busMask & dataMask * 8の部分です。
まずaddr & ~busMaskですが、バス幅で割った余りのアドレスを求めています。
例えば、幅が64bitsでアドレスが0x12ならば、8で割った余りのアドレス0x02を求めています。
次にaddr & ~busMask & dataMaskですが、データ幅境界にアドレスを揃えています。この意味と必要性の議論は後述します。
例えばデータ幅が16bitsならば、アドレスを2の倍数にします。アドレス0x01なら0x00、アドレス0x02なら0x02、アドレス0x03なら0x02です。
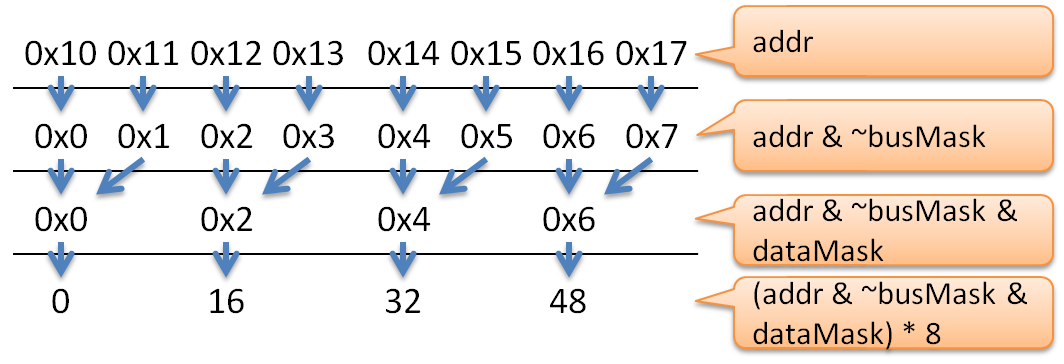
残りの処理はアドレスに8を掛けて右ビットシフトしています。関数の返値は上位に余計なデータが残っていますので、返り値を受け取った人は、余計な上位のデータを捨てる必要があります。

呼び出す側のコードは、こんな感じです。
呼び出し側の例
//データバス幅
public static int BITS_DATA_BUS = 64;
public byte read8(long addr) {
return (byte)readMasked(addr, readWord(addr), BITS_DATA_BUS, 8);
}
public short read16(long addr) {
return (short)readMasked(addr, readWord(addr), BITS_DATA_BUS, 16);
}
public int read32(long addr) {
return (int)readMasked(addr, readWord(addr), BITS_DATA_BUS, 32);
}
他のアドレスが渡される場合も同様です。


他のバス幅、他のビット幅でも同じ考え方で処理可能です。

データ幅の境界にアドレスを揃える意味
データ幅境界以外からデータを読んで良い、つまり0x13から読んだときに0x0246ではなくて、0x7802を返せるシステムならば、& dataMaskは不要です。

この方が便利ですが良いことばかりでもなく、バス幅をまたぐ際の読み出し、例えば0x17から16bits読む際の処理が必要になります。
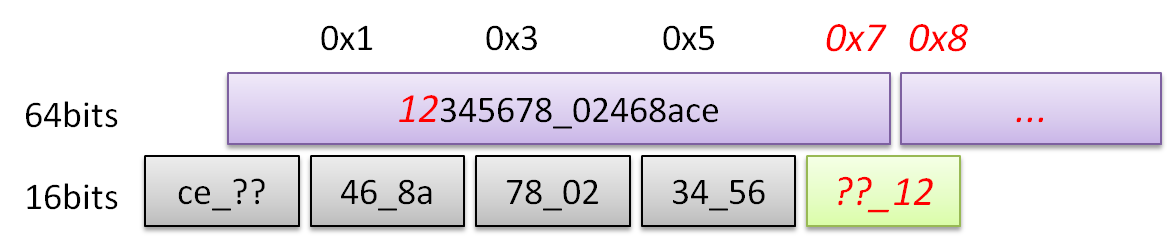
しかし前述のコードではバス幅の境界をまたぐ読み出し方に対応できませんから、データ幅境界以外からデータを読めないようにして、異常動作しないように防いでいます。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2014年5月25日
企業も生きている
企業の生涯を追うと、若い時は素早くて何でもチャレンジするけれど、時が経つと緩慢で億劫になって何もしなくなり、やがて体が動かなくなって息絶えるんです。
なんか、企業と生き物って似ているなーと思ったら、色々浮かんできました。
- 不採算部門のレイオフ
- 内臓切るような外科手術、あるいはスタンガンですかね。体力が激減するし、調子に乗って何度もやればショック死です。
- 税金での救済
- 死体のゾンビ改造術のようなもん?ゾンビは周りにいる健康な人を襲うため、市場に悪影響が出る、ってな感じです。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
2014年5月24日
はじまりとおわり
国道には○○号線、と番号が振られていて、重なっている区間もあります。中には始点や終点が別の国道と重なっている場合もあります。
じゃあ、国道の始まりと終わりは誰が決めるのか?と疑問に思い調べてみると、道路法に基づいた「一般国道の路線を指定する政令」(昭和四十年三月二十九日政令第五十八号)という政令で決められているそうです。
道路法といい、政令といい、何の捻りもないストレートな名前です。わかりやすいのでありがたくもあり、あまりにあっさり見つかったのでやや物足りなくもあり。うーん…。
試しに一つ調べてみる
我が家からもっとも近い国道はR171です。試しにR171について調べてみましょう。
先の政令58号によれば、国道171号線の起点は京都市、終点は神戸市です。重要な経過地は、向日市、長岡京市、京都府乙訓郡大山崎町、高槻市、茨木市、箕面市、池田市、伊丹市、尼崎市、西宮市(河原町)、芦屋市(清水町)です。
あれ?これだけ?どうも政令58号では具体的な位置(交差点名、何号線に吸収される、など)は言及していないようです。
詳細な位置
道路整備促進期成同盟会全国協議会が発行していた「道路時刻表」によると、道路を走行した際の所要時間の概算値を見ることができます。
走行時間の付属情報として、始点、主な交差点(と交差する道)、終点も書いてあるため、どこで何の道が重なっているかがわかります。本来の用途と異なる使い方ですが、この際わかれば何でも良いのです。
が、しかし道路時刻表は2008年で絶版とのこと。うーん、最新の情報はどこにあるんですかねえ…。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2014 | > | ||||
| << | < | 05 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | - | 1 | 2 | 3 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
最近のコメント5件
最近の記事20件
-
 21年7月10日
21年7月10日
すずき (06/02 21:25)
「[OpenOCD - まとめリンク] 目次: OpenOCDOpenOCDとHiFive UnleashedのSPI Flas...」 -
26年6月2日
すずき (06/02 21:25)
「[OpenOCDのビルド2026] 目次: OpenOCD以前(2023年6月28日の日記参照)紹介したときからビルド方法が変...」 -
22年3月18日
すずき (05/28 01:34)
「[射的 - まとめリンク] 目次: 射的ガスガン その1ガスガン その2ガスガンが増えました射的射的2回目射的3回目東京マルイ...」 -
26年5月24日
すずき (05/28 01:34)
「[JTSA Unlimited大会参加2026] 目次: 射的JTSA Unlimitedの大会に参加しました。「水」ステージ...」 -
26年5月16日
すずき (05/21 02:14)
「[「かに」で終わる形容動詞] Xで50音順に「かに」で終わる形容動詞(正確には連用形ですが)を並べている人がいて、面白そうなの...」 -
26年5月3日
すずき (05/08 20:51)
「[農家はREPLACE()されました、を9割クリア] 目次: ゲーム大昔にちょっとだけやって中断していたゲーム「農家はREPL...」 -
21年12月28日
すずき (05/06 19:21)
「[ゲーム - まとめリンク] 目次: ゲームNintendo DSを買ったパネルでポンDS最近の朝はパネポンDS聖剣伝説DSチ...」 -
26年4月29日
すずき (05/06 02:41)
「[ぽこあポケモンをクリア] 目次: ゲーム1日だけやって放置していたぽこあポケモンをクリア(=スタッフロールが流れるイベントを...」 -
26年4月7日
すずき (04/07 23:02)
「[ジャガーさんのエンジンオイル交換] 目次: 車買ってから6,000kmくらい走ったのでエンジンオイル&オイルフィルターを交換...」 -
23年5月15日
すずき (04/07 21:52)
「[車 - まとめリンク] 目次: 車三菱 FTO GPX '95の話。群馬県へのドライブ1群馬県へのドライブ2将来車を買い替え...」 -
26年2月8日
すずき (04/07 21:51)
「[ジャガーさんの修理……のはずが雪] 目次: 車以前(2025年11月21日の日記参照)、ジャガー...」 -
26年4月4日
すずき (04/07 21:51)
「[ジャガーさんのワイパー交換] 目次: 車以前からジャガーのワイパーは中央部分だけ拭き取れておらず、前が見づらかったです。最近...」 -
26年4月5日
すずき (04/07 00:04)
「[ドラクエ2リメイク、トロフィーコンプ] 目次: ゲームSteamで買ったドラクエ1&2 HDリメイク、ついにドラクエ2もトロ...」 -
26年3月20日
すずき (03/26 01:31)
「[Upload Labs、トロフィーコンプ] 目次: ゲーム先月、Upload Labsのトロフィーをコンプリートしましたが、...」 -
26年3月6日
すずき (03/19 02:54)
「[CRCの計算その2 - 最上位ビットの省略] 目次: ベンチマーク前回、CRCの筆算とMSBに寄せていくCRCの計算方法を紹...」 -
21年5月22日
すずき (03/19 02:54)
「[ベンチマーク - まとめリンク] 目次: ベンチマーク色々なベンチマーク、コードゴルフ。USB HDD RAIDのベンチマー...」 -
26年3月2日
すずき (03/19 02:53)
「[CRCの計算その1 - 筆算] 目次: ベンチマーク令和の時代に今更ですがCRCについて調べてました。CRCのベースになる数...」 -
26年3月10日
すずき (03/13 00:54)
「[誕生日] 43歳になりました。昨年の日記(2025年3月10日の日記参照)を見ると、転職して半年というのもあって通勤の話をし...」 -
22年4月13日
すずき (03/12 23:48)
「[C言語とlibc - まとめリンク] 目次: C言語とlibcC言語について。C++言語もたまに。プログラムの落とし穴、演算...」 -
07年11月1日
すずき (03/12 23:47)
「[netcatとsigned charとunsigned char] 目次: C言語とlibcGNU netcat 0.7.1...」
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
