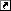
2017年11月22日
アイス履歴
アイス履歴を10個ほど増やしました(リンク)。これで55種類かな。そろそろカウントが面倒になってきました…。
最近はパピコやモナカのような棒アイス以外にも手を出しているので、アイスの袋の増え方が激しくアップロードしきれていません。そのうち載せます。
夏、秋は果実系のさわやかなアイスがおいしい季節でしたが、冬は味濃い系が恋しくなります。個人的にまた発売してほしいなー、と思うアイスは、
- 赤城乳業 ミルクレア スイーツ ラムレーズン
- 明治 ゴールドライン フランボワーズ
- ロッテ カスタードとろけるほろにがカラメルのプリンアイスバー
辺りですね。他のアイスもおいしいです。ぜひ見かけたら食べてみてください、と言いたいところですが、アイスは商品の入れ替わりが激しくて、すぐにお店から消えるんですよねえ……。
その反面、アイスはほぼ毎週と言って良いほど、新商品が出ていてマンネリとは無縁です。メーカーさんの努力は素晴らしいです。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2017年11月24日
モナコイン
目次: ベンチマーク
仮想通貨の勉強がてら、モナコイン(以外の仮想通貨にも対応してますが)のマイナーcpuminer-multiを見ていました。かなり最適化されていて、迂闊にSSEを使うと逆に遅くなるほどです。面白いです。
モナコインのハッシュアルゴリズムはLyra2REv2という名前の256ビットハッシュ関数で、複数のハッシュ関数の組み合わせでできています。
- blake
- keccak
- cubehash
- LYRA2
- skein
- cubehash(2回目)
- bmw
上から順に実行されます。先頭のblakeへの入力は80バイトで、出力は32バイト。1つ前のハッシュ関数の出力が、2番目以降のハッシュ関数の入力となります。LYRA2だけパラメータが2つ(saltとpassword)必要ですが、どちらも同じ値を指定していました。
Lyra2REv2をCPUで演算する場合CubeHashに一番時間が掛かります。2回実行されることを差し引いて考えても遅いです。見ていると最終ラウンドが160回という設定になっていて、これが異常に遅いみたいです。
実装(=cpuminer-multiの最適化された実装)を見ると、このハッシュ関数は4ワードと別の4ワードをペアにして演算をします。ワーク領域は32ワードありますので、同じ演算が4回実行されます。いかにもSSEに向いていそうな処理ですが、4ワードの組み合わせ方が変わるので、SSEレジスタにうまくパッキングできません。
- (EVENラウンド)
- 加算★
- 左ローテート
- XOR★
- 2ワードずらして加算
- 左ローテート
- 2ワードずらしてXOR
- (ODDラウンド)
- 逆順で加算
- 左ローテート
- 逆順でXOR
- 逆順2ワードずらして加算
- 左ローテート
- 逆順2ワードずらしてXOR
試しに★の部分だけ、単純にSSEを使ったら、余計遅くなりました。切ない。どうもSSEレジスタからのロード/ストアで引っかかって遅くなっているようです。しかしSSEには左ローテート演算がないため、左ローテートの前に必ずストアしなければなりません。
EVEN + ODDのラウンドが8回繰り返されますが、安易にunrollingしても(※)やはり遅くなります。unrollingした後のマシン語を見ると嫌になるくらい長いので、命令キャッシュのヒット率が落ちてるのかな?
うーん、難しいです……。
(※)私が何かしたわけではなくcpuminer-multiにはunrollingするコンパイルオプションが用意されていて、それを使ってみただけです。CubeHash以外のハッシュ関数もunrollingするかしないかを選べます。素敵な作りです。
CubeHash
そもそもCubeHashって何なのか全く知らないので調べてみました。Wikipediaの解説(リンク)がとても親切です。CubeHashはNISTのハッシュ関数コンペに応募されたものなのだとか。次のSHAなんちゃらに採用されるかもしれないですね。
CubeHashにはパラメータがあり、パラメータが違うと全く違うハッシュ関数になります。Lyra2REv2で使用しているのはどれ、という情報が見当たらなかったのですが、cpuminer-multiの実装(初期ラウンドは不明ですが、1周16ラウンド、ブロックサイズ32ビット、最終160ラウンド、ハッシュ長256ビット)から推測するにCubeHash160+16/32+160-256じゃないか?と思われます。長い名前だなあ……。
キューブは4個あって、i, jの2次元で指定されます。i, jは0か1の値しかとりません。
キューブは8個のブロックから構成されk, l, mの3次元で指定されます。k, l, mも0か1の値しか取りません。
ブロックは32ビットです…、というよりLyra2REv2のCubeHashの場合は32ビット、と言った方が正しいですね。
従って、全体で4 * 8 = 32個のブロックが存在します。Wikipediaの図ではi, j, k, l, mという5次元のアドレスで表現していますが、計算の際はi, j, k, l, mをくっつけて2進数だと思って数値に変換します。
例えば、右下のキューブ(i = 1, j = 0)、右上の手前側ブロック(k = 1, l = 1, m = 0)だったら、ijklm = 10110 = 22になりま…、はい?わかりづらい?
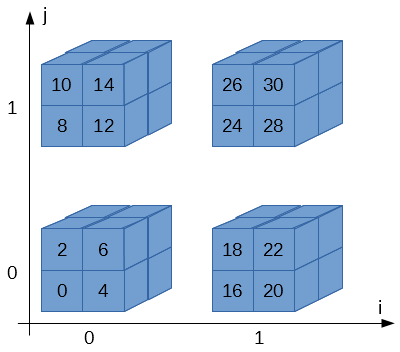
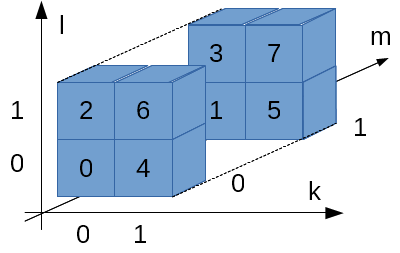
これでわかりやすい?
CubeHashの素朴な実装
Wikipediaに載っている実装をそのまま実装すれば良いです。と言われてやる人は居ませんから、自分でやってみます。
アルゴリズムだけ実装しても、結果を確かめる術がないのでcpuminer-multiに組み込める形で実装します。sha3/sph_cubehash.cにSIXTEEN_ROUNDSというマクロがあって、CubeHashの1周(16ラウンド)に相当しています。このマクロを改造して自作の実装を差し込みます。
CubeHashの素朴な実装、準備編
#if 1 //今から作る実装を無理やり有効にする
#define SIXTEEN_ROUNDS do { \
int j; \
for (j = 0; j < 16; j ++) { \
ROUND_ONE; \
} \
} while (0)
#elif SPH_CUBEHASH_UNROLL == 2 //#ifを #elifに変えてしまう(SPH_CUBEHASH_UNROLLオプションを無視)
#define SIXTEEN_ROUNDS do { \
int j; \
for (j = 0; j < 8; j ++) { \
ROUND_EVEN; \
ROUND_ODD; \
} \
} while (0)
次にラウンドの処理を書きます。Wikipediaを見ながら10個の手順をそのまま書きます。
CubeHashの素朴な実装
void sw(uint32_t *a, uint32_t *b)
{
uint32_t tmp = *b;
*b = *a;
*a = tmp;
}
#define ROUND_ONE do { \
int i; \
uint32_t *b = (sc)->state; \
/* STEP 1, 2 */ \
for (i = 0; i < 16; i++) { \
b[i + 16] += b[i]; \
b[i] = ROTL32(b[i], 7); \
} \
/* STEP 3 */ \
for (i = 0; i < 8; i++) { \
sw(&b[i], &b[i + 8]); \
} \
/* STEP 4 */ \
for (i = 0; i < 16; i++) \
b[i] ^= b[i + 16]; \
/* STEP 5 */ \
for (i = 0; i < 4; i++) { \
sw(&b[16 + i * 4], &b[18 + i * 4]); \
sw(&b[17 + i * 4], &b[19 + i * 4]); \
} \
/* STEP 6, 7 */ \
for (i = 0; i < 16; i++) { \
b[i + 16] += b[i]; \
b[i] = ROTL32(b[i], 11); \
} \
/* STEP 8 */ \
for (i = 0; i < 4; i++) { \
sw(&b[0 + i], &b[4 + i]); \
sw(&b[8 + i], &b[12 + i]); \
} \
/* STEP 9 */ \
for (i = 0; i < 16; i++) \
b[i] ^= b[i + 16]; \
/* STEP 10 */ \
for (i = 0; i < 4; i++) { \
sw(&b[16 + i * 4], &b[17 + i * 4]); \
sw(&b[18 + i * 4], &b[19 + i * 4]); \
} \
} while (0)
コンパイルして動けばOKです。
実行例
$ ./cpuminer -a lyra2rev2 -t 1 --benchmark ** cpuminer-multi 1.3.3 by tpruvot@github ** BTC donation address: 1FhDPLPpw18X4srecguG3MxJYe4a1JsZnd (tpruvot) [2017-11-24 20:25:06] 1 miner threads started, using 'lyra2rev2' algorithm. [2017-11-24 20:25:07] CPU #0: 68.54 kH/s [2017-11-24 20:25:07] Total: 68.54 kH/s [2017-11-24 20:25:11] Total: 80.77 kH/s [2017-11-24 20:25:16] CPU #0: 80.76 kH/s [2017-11-24 20:25:16] Total: 80.76 kH/s
もし高速化に挑むのであれば、ハッシュ関数の出力する結果が合っているかどうかも見た方が良いです。基本的には、変更前の結果と比べて同じかどうかをチェックします。まあ、マイニングプールに繋いでみてacceptが返ることでも確かめられますけど、マイニングプールに迷惑なのでほどほどにね……。
コンパイラの本気を見よ
この素朴な実装はとても遅いです。我が家のマシン(AMD A10-7800/3.5GHz)では、最適化レベルが -O2でも33kH/s程度しか出ません。cpuminer-multiの元々の実装(unrolling = 2)は80〜81kH/sくらいなので、天と地ほどの差があります。
元のcpuminer-multiの実装が速い理由は、ラウンドのswap処理を手動で解決し、2ラウンド分をunrollingしているからだと思われます。swapを手動展開するところで、記号の意味が訳わからなくなってしまうため、読むのはだいぶキツいものがあります。
ところがそこまでしなくても、実は -Ofast -march=nativeで最適化を掛けると79〜80kH/s程度と、かなり近い速度が出せてしまいます。出力されたコードはSSEによるベクタ化や命令並べ替えの多発で、人間には理解不能な感じになっちゃってますが、まーとにかく速いです。コンパイラの本気を見た気がしますね。
コメント一覧
- すずきさん(2017/11/26 17:09)
SHA-3 はもう決定していて、keccak が採用されたそうです。
Wikipedia をちゃんと読んだら 「CubeHash は 2回戦までは行ったが、最終選考の 5つに残れなかった」と書いてありました。
この記事にコメントする
| < | 2017 | > | ||||
| << | < | 11 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | 1 | 2 | 3 | 4 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | - | - |
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
