2018年8月15日
自分のマシンは何GFLOPSか? その3
LINPACKを単独のマシンで実行してもあまり面白くないので、クラスタで実行したいと思います。役割としてはマスタが1台、スレーブが他全部という分担になります。LINPACKの場合、マスタからスレーブにsshでログインして、ログイン後xhplを実行するようです。
スレーブ側の設定
スレーブ側はLINPACKをコンパイルして、xhplをマスタと同じパスに配置すればOK です(HPL.datは要らない)。マスタ側のバイナリが /home/username/a/b/c/xhplに置かれているとしたら、スレーブ側も同じ /home/username/a/b/c/xhplディレクトリに置かなければ起動できないようです。
一番簡単なのはマスタ、スレーブ、全てのノードに同じユーザを作成して、MPI実行用のバイナリを入れるディレクトリを作成することですね。
さらにスレーブはsshの公開鍵認証にしておくと、LINPACK起動時にパスワードを打たなくて良いので楽です。マスタからスレーブにログインできればOKで、スレーブからマスタにログインする設定は不要です。
マスタ側の設定
マスタ側はLINPACKをコンパイルするのは当然として、少しだけ特別な設定が必要です。私はhostfileの存在に気づくまでにかなり時間がかかりました…。
- HPL.dat: 単独で実行していたときにも使っていたLINPACKパラメータを書いたファイル
- hostfile: クラスタのノード一覧を書いたファイル
HPL.datは単独動作と同じで良いです。性能は後で考えるとして、とりあえず動作するはずです。
クラスタのノード一覧hostfileは単独のときには使っていませんでした。基本的にはクラスタを構成するノードのホスト名(IPアドレスでも良いです)を並べるだけです。
hostfileの記述例
localhost slots=4
192.168.1.109 slots=4
上記は2台構成(ROCK64がlocalhost、Raspberry Pi 3が192.168.1.109)の記述です。slots= にはそのノードがいくつのプロセスを扱えるかを記述します。どちらも4コア4スレッドのCPUなのでslots=4としています。まあ2とか8とかにしても動きますが、効率は下がります。
クラスタ起動
実行は下記のようにします。ROCK64がマスタ、Raspberry Pi 3がスレーブです。下記のコマンドはマスタ側で実行してください。
クラスタでのLINPACK実行
$ cd bin/Linux_ATHLON_CBLAS $ ls HPL.dat hostfile xhpl $ mpirun -n 8 -hostfile hostfile -host localhost,192.168.1.109 xhpl ... ================================================================================ T/V N NB P Q Time Gflops -------------------------------------------------------------------------------- WR00L2L2 2000 64 1 4 3.74 1.429e+00 HPL_pdgesv() start time Wed Aug 15 00:11:49 2018 HPL_pdgesv() end time Wed Aug 15 00:11:53 2018 -------------------------------------------------------------------------------- ||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0037309 ...... PASSED ...
MPIの凄いところはROCK64(arm64)とRasPi(arm)のようにアーキテクチャが違うクラスタでも実行できてしまうところです。メッセージパッシングの隠れた利点かもしれません。
動作しているかどうか確認するにはRaspberry Pi 3側でtopなどで見るのが確実だと思います。LINPACK実行中にxhplが4プロセス実行されているはずです(全力で実行した場合)。
ちなみにhostfileを指定し忘れるとこんなエラーになります。8プロセス起動しろと言われても、どのノードがプロセスをいくつ受け持ってくれるかわからないので、怒っている訳ですね。
hostfileを指定し忘れるとこんなエラー
$ mpirun -n 8 -host localhost,192.168.1.109 xhpl -------------------------------------------------------------------------- There are not enough slots available in the system to satisfy the 8 slots that were requested by the application: xhpl Either request fewer slots for your application, or make more slots available for use. --------------------------------------------------------------------------
それとOpenMPIのバージョンには注意してください。我が家のデスクトップPC(Debian Testing, OpenMPI 3.1.1)とファイルサーバ(Debian Stable, OpenMPI 2.0.2)でx86_64クラスタを構成しようとしたところ、OpenMPIのバージョン違いでこんなエラーになって実行できませんでした。
OpenMPIのバージョン違いだとこんなエラー
$ mpirun -n 4 -hostfile hostfile -host localhost,falcon xhpl [blackbird:29131] tcp_peer_recv_connect_ack: invalid header type: 0★★★★こんなエラーで怒られる★★★★ -------------------------------------------------------------------------- ORTE was unable to reliably start one or more daemons. This usually is caused by: * not finding the required libraries and/or binaries on one or more nodes. Please check your PATH and LD_LIBRARY_PATH settings, or configure OMPI with --enable-orterun-prefix-by-default * lack of authority to execute on one or more specified nodes. Please verify your allocation and authorities. * the inability to write startup files into /tmp (--tmpdir/orte_tmpdir_base). Please check with your sys admin to determine the correct location to use. * compilation of the orted with dynamic libraries when static are required (e.g., on Cray). Please check your configure cmd line and consider using one of the contrib/platform definitions for your system type. * an inability to create a connection back to mpirun due to a lack of common network interfaces and/or no route found between them. Please check network connectivity (including firewalls and network routing requirements). --------------------------------------------------------------------------
エラーメッセージはたくさん出ますが、解決に辿り着かないので何とも言えない気分です…。
肝心の性能は
結論から言ってしまえばROCK64とRaspberry Pi 3のクラスタは意味がなさそうです。なぜならROCK64 1台のほうが速いからです…。
まずは単独実行と同じ問題サイズN=2000での実行結果です。多少上下しますが0.6〜0.7GFlopsくらいです。ROCK64単独(1.4GFlops)の半分以下です。P, Qの値は2, 4が一番良さそうでした。他の値(1, 8や4, 2)にすると激遅で実行が終わりません。
ROCK64, Raspberry Pi 3の2台クラスタN=2000
$ mpirun -n 8 -hostfile hostfile -host localhost,192.168.1.109 xhpl ... ================================================================================ T/V N NB P Q Time Gflops -------------------------------------------------------------------------------- WR00R2L4 2000 64 2 4 7.97 6.699e-01 HPL_pdgesv() start time Wed Aug 15 00:41:15 2018 HPL_pdgesv() end time Wed Aug 15 00:41:22 2018 -------------------------------------------------------------------------------- ||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0037423 ...... PASSED ================================================================================ T/V N NB P Q Time Gflops -------------------------------------------------------------------------------- WR00R2C2 2000 64 2 4 7.94 6.724e-01 HPL_pdgesv() start time Wed Aug 15 00:41:23 2018 HPL_pdgesv() end time Wed Aug 15 00:41:31 2018 ...
問題サイズが小さすぎたかな?と思いN=4000にしてみました。0.9〜1.3GFlopsとだいぶ性能が上がります。単独実行の場合N=2000とN=4000ではほぼ性能に変化はありません。
ROCK64, Raspberry Pi 3の2台クラスタN=4000
$ mpirun -n 8 -hostfile hostfile -host localhost,192.168.1.109 xhpl ... ================================================================================ T/V N NB P Q Time Gflops -------------------------------------------------------------------------------- WR00L2L2 4000 64 2 4 32.17 1.327e+00 HPL_pdgesv() start time Wed Aug 15 00:50:32 2018 HPL_pdgesv() end time Wed Aug 15 00:51:04 2018 -------------------------------------------------------------------------------- ||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.0018773 ...... PASSED ================================================================================ T/V N NB P Q Time Gflops -------------------------------------------------------------------------------- WR00L2L4 4000 64 2 4 40.92 1.043e+00 HPL_pdgesv() start time Wed Aug 15 00:51:04 2018 HPL_pdgesv() end time Wed Aug 15 00:51:45 2018 ...
性能が違うノードを組み合わせているからなのか、放熱が足りなくてオーバーヒートしているのか、性能がかなり不安定です。たまにSystem負荷が50%台に張り付いて、実行が終わらなくなるときもあります。うーん、たった2台でも難しいものだな。
コメント一覧
- すずきさん(2018/08/15 10:35)
さすがに x86_64 と arm のクラスタは無理みたい。エラーになってしまう。 - すずきさん(2018/08/15 10:42)
実行できた。あと実行ファイルパスについて、大きく勘違いしていた。実行ファイルのパスを完全に合わせないとダメみたい。 - すずきさん(2018/08/15 10:52)
うーん、なんか暴走したり、動かなかったり、うまくいかない。素直に同じアーキテクチャのマシンをたくさん用意したほうが良さそう。
 この記事にコメントする
この記事にコメントする
2018年8月14日
自分のマシンは何GFLOPSか? その2
LINPACKのビルドができたので、さっそく実行してみます。バイナリはbinディレクトリの下にあります。
実行の仕方はmpirun -n 4 xhplのようにします。パラメータファイル(HPL.dat)が置いてあるディレクトリで実行してください。
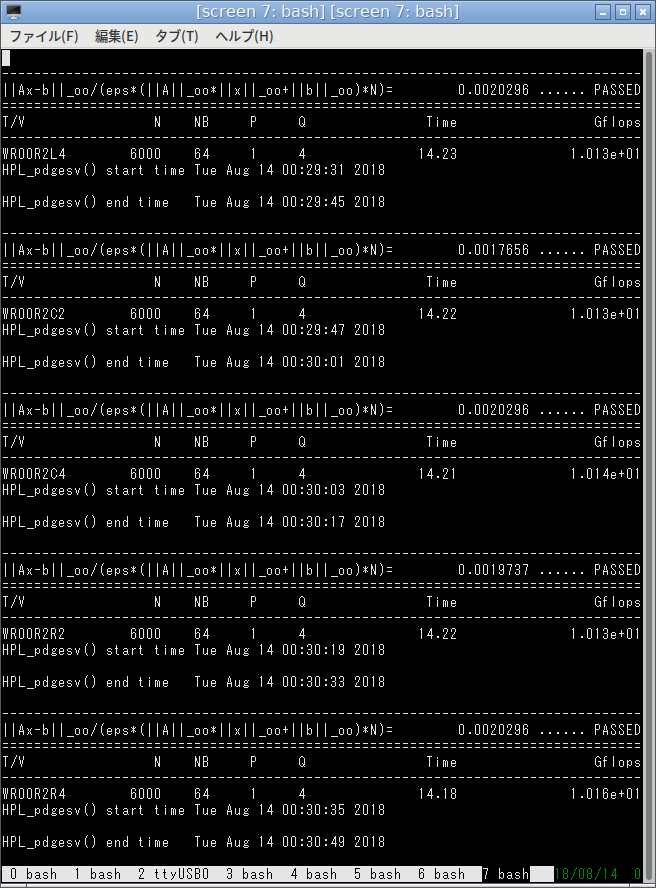
これが最速パラメータかどうか自信がありませんが、とりあえず10GFlopsだそうです。
しかしhdk氏のAMD A10-7870Kは19GFlops出ているそうです。両者ともにBulldozer系のAPUなのに、倍も差がつく理由がさっぱりわかりません。謎です…。
AMD A10-7800の性能(追記)
何気なくcblasとatlasのスタティックリンクをやめて、ダイナミックリンクに変更したところ、いきなり性能が上がり1.7倍の17GFlopsになりました。
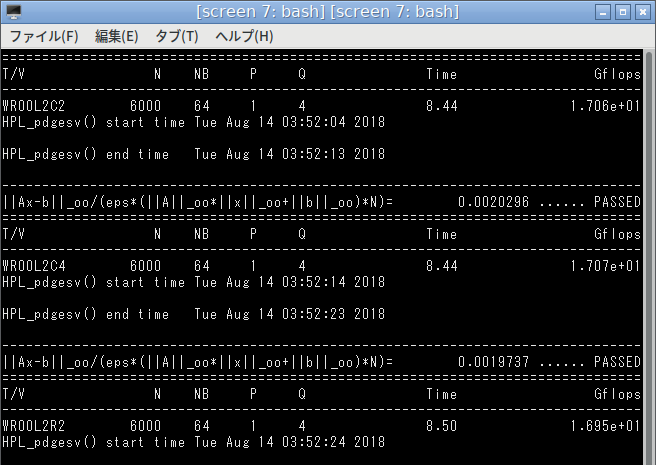
AMD A10-7800での実行結果(ダイナミックリンク版)
えー?なぜ!?とりあえずperf topで見てみるとlibatlas.soの関数が8割ほどの実行時間を占めています。ここが効率的になったんでしょうか?そんなに変わるものですかね、さっぱり意味がわかりません…。
ARMも見てみる
ROCK64でも実行してみました。SoCはRockchip RK3328、CPUはCortex-A53 x 4 です。
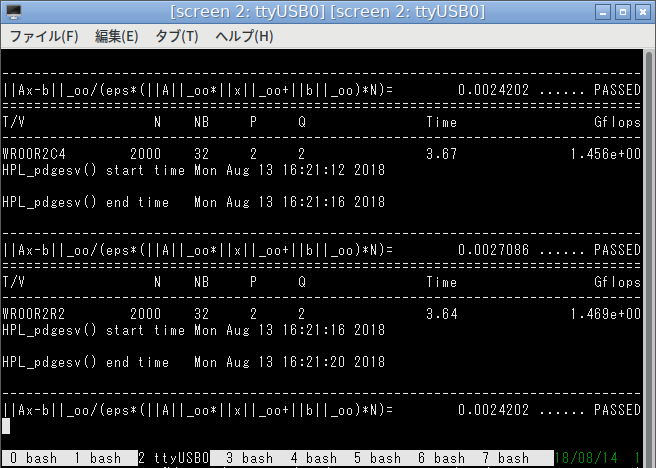
大体1.5GFlopsでした。A10-7800と比べるとやはり1桁違いますね(PCが6.7倍速い)(ダイナミックリンク版だと11倍速い)。
コンパイル実験(2018年8月12日の日記参照)のときはPCが18倍ほど速かったので、コンパイル実験よりは差が縮まっている、とも取れます。
電力効率の点から見ると、PC 1台よりROCK64を10台並べた方が省エネなのでしょうか?微妙かな…?今度、ワットチェッカーで比べてみましょうか。
コメント一覧
- hdkさん(2018/08/14 23:06)
なるほど! LINKERを変えていなくてリンクエラーになるのを何とかしようとして手こずっている間に-lcblas -latlasに変えていました... まさかそれが実行時間を短縮するとは... - すずきさん(2018/08/15 08:34)
ダイナミックリンクにするだけで性能がほぼ倍になるので、私も驚きです…。
この記事にコメントする
2018年8月13日
自分のマシンは何GFLOPSか? その1
自分のマシンは何GFLOPSか知りたくなって、スパコン界隈で有名なLINPACKを実行してみようと思い立ちました。ソースコードは HPL- A Portable Implementation of the High-Performance Linpack Benchmark for Distributed-Memory Computers にあります。私はhpl-2.2.tar.gzを使用しました。
ビルド方法はINSTALLファイルに書いてある通りですが、結構ハマったので、私の手順もメモしておきます。環境はDebian GNU/Linux Testingのamd64版です。
LINPACKのMakefile
コードを展開し、setupディレクトリの下にあるMake.xxxをトップディレクトリにコピーして使います。たくさんファイルがありますが、AthlonマシンなのでLinux_ATHLON_CBLASを選びました。FBLASという名前のファイルもありますが、
- CBLAS: C版
- FBLAS: Fortran版
のようです。用語の意味はわかりませんが、Makefileのdiffを見れば何となくわかるはず、きっと。
ビルドの準備
コピーしてきたMake.Linux_ATHLON_CBLASは書き換える必要があります。特に大事なのはTOPdirです。
この変更を忘れるとホームディレクトリ直下のhplというディレクトリがトップディレクトリだと思って、ビルドを始めます。最終的に「Make.incが見つからない」と言われて失敗します。
Make.incをfindで探すとわかりますがMake.incはシンボリックリンクです。ビルドに失敗するときはMake.incが全然関係ない場所を指していると思います。
もしTOPdirを書き換え忘れてビルドが失敗した場合はmake arch=Linux_ATHLON_CBLAS clean_archとしてください。アーキテクチャ名の付いたディレクトリ(Make.incもそのディレクトリに入っている)が全て消滅するはずです。
書き換え箇所
# TOPdirをソースコードを配置した位置に合わせて修正します TOPdir = ... # コンパイラをgccからmpiccにします CC = /usr/bin/mpicc # リンカもgccからmpiccにします LINKER = /usr/bin/mpicc # OpenMPIのライブラリ位置 MPdir = /usr/lib/x86_64-linux-gnu MPinc = -I$(MPdir)/openmpi/include # ビルドしたバイナリが動かなくなるため、MPlibは削除 #MPlib = ... # LAlibのライブラリ位置 LAdir = /usr/lib/x86_64-linux-gnu # スタティックリンクだとなぜか遅いので、ダイナミックリンクに変更 LAlib = -lcblas -latlas # 末尾に -lrt -lbacktraceを追加します。 # HPL_LIBSの先頭に追加するとリンクエラーになります。 HPL_LIBS = ... -lrt -lbacktrace
あと、私の環境の場合、下記パッケージのインストールが必要でした。
- libopenmpi-dev
- libmpich-dev
- libatlas-base-dev
実行はまた今度にします。
コメント一覧
- hdkさん(2018/08/14 00:11)
LINKERも変えるんですかね(ちゃんと理解してない) - すずきさん(2018/08/14 00:20)
あ、そうでした、LINKER も mpicc に変えないと、めちゃくちゃエラーが出ます…。 - すずきさん(2018/08/14 00:33)
LINKER の記述も足しておきました。 - すずきさん(2018/08/14 12:34)
LAlib をダイナミックリンクにする記述も足しました。
この記事にコメントする
2018年8月12日
ARM PCで開発できるか?
目次: ARM
最近のARM搭載SoCはかなり速くなっています。もしかしてx86 PCの代わりに使えるのではないでしょうか?開発に使うことを想定して、コンパイル速度を比較してみたいと思います。
比較に使うのはLinux Kernelの開発ツリー(linux-next)です。コンフィグはデフォルトを使い、ビルドターゲットはallを指定します。ビルドしているアーキテクチャが違う(ROCK64: arm64, AMD A10: x86)ので、時間の単純比較はできませんが、参考にはなると思います。
AMD A10 7800、32GB DDR3-1600のPCでlinux-next x86のtime make -j4 allを実行しますと、
- real 10m33.584s
- user 33m37.811s
- sys 4m7.908s
不遇のBulldozer系コア、もはや4年落ちとなったCPUで、大して速くはありませんが、十分実用的というか、待っていられるレベルです。
Intel Pentium J4205、16GB DDR3L-1600のPCでlinux-next x86のtime make -j4 allを実行すると、
- real 14m45.968s
- user 51m57.967s
- sys 5m47.331s
Pentium JはAtom系列で遅いと思いきや、予想より何倍も速かったです…。ナメてました、ごめんなさい。
ROCK64、Rockchip RK3328、Cortex A53 x 4、4GB DDR3でlinux-next arm64のtime make -j4 allすると、
- real 179m33.126s
- user 266m0.254s
- sys 22m52.046s
PCと比較するとほぼ1桁遅いです。さすがにこれは待っていられません。ROCK64は普段使いには十分速いですが、開発に使うのは辛そうですね…。
Raspberry Pi 3、Broadcom BCM2837、Cortex A53 x 4、1GB LPDDR2でlinux-next armのtime make -j4 allすると、
- real 146m46.807s
- user 236m43.970s
- sys 10m41.310s
ビルドしているアーキテクチャが違う(ROCK64はarm64、RasPi 3はarm)ので、単純比較はできませんけど、ROCK64と大差ないですね。
もっと速いARM SoCは?
今のところスマホ、TV/STB系ARM SoCはA72 x 4、A53 x 4が最強クラスのようです。サーバー系ARM SoCに目を向ければA72 x 16(NXP LX2160A)もしくはA53 x 24やA53 x 48(Cavium ThunderX)といった桁違いメニーコアがありますが、そんなに要らないんですよね…。
中間の製品はありません。買う人いないんでしょうね。
ARM SoC搭載ボード
今後のお買い物の参考に、ざざっと調べてみました。
- Tegra系
- ボードJetson TX2、Denver x 2、A57 x 4、8GB LPDDR4、$600日本だと販売店のぼったくりで10万円。
- HiSilicon Kirin 960
- ボードHiKey 960、A72 x 4、A53 x 4、3GB LPDDR4、$239良いんだけど、メモリがもう一声欲しかった…。
- Rockchip RK3399
- ボードNanoPC-T4、A72 x 2、A53 x 4、4GB LPDDR3-1866、$109 DDR3ではあるけど、良さそう。
- Samsung S5P6818
- ボードNanoPC-T3 Plus、A53 x 8、2GB DDR3、$75可もなく不可もなく?
- Amlogic S912
- ボードが見当たらない、A53 x 8、どこか発売してくれないかな。
- Amlogic S905
- ボードODROID C2、A53 x 4、2GB DDR3、$39 S912の一世代前ですね。
- AllWinner H6
- ボードPINE H64、A53 x 4、2GB LPDDR3-1600、$36安くて素敵だけど、さすがに見劣りしてしまうなあ。
性能だけ求めるならJetsonかHiKey 960で、コスパならNanoPC-T4ですかね。Jetsonなら流行りのAIとか、GPGPUも実験できますね。お値段はべらぼうですけど…。
コメント一覧
- すずきさん(2018/08/14 13:32)
Raspberry Pi 3 の結果も足しておいた。 - ARM926EJ-Sさん(2025/05/29 14:27)
この記事が書かれたのは2018年ですが、2025年のArmはたいへん速くなりましたね...
ARM自身も高速なIPをバンバン打ち出して、すごいものです。 - すずきさん(2025/05/29 16:57)
コメントありがとうございます。
この辺りの日記でARMとRISC-Vを比較していたんですが、
https://www.katsuster.net/index.php?arg_act=cmd_show_diary&arg_date=20221222
今のA78辺りは、この時代のA72、A73に比べて格段に速くなりました。ARMの努力はすごいなあと思います。
この記事にコメントする
2018年8月11日
地震保険
AIG損害保険から「大阪北部地震で被害を受けた方はご連絡ください」という手紙が来て、地震保険に加入していたことを知りました。ずっと火災保険だと思ってたよ……。
人生初の地震保険です。
保険会社に被害を申請(電話、Webでも可能)すると、調査員さんが家に来てくれます。調査員の方は、かなり積極的に被害としてカウントしてくれます。むしろ、こちらが「いやー、そこは特に被害無かったですね…」と断るような形になるくらいでした。
家財の場合、壊れなくても、地震で倒れたりズレたら被害としてカウントされるそうです。あと、地震保険で特徴的なのは、被害を受けた「種類」が大事なことです。本が1冊でも100冊でも、カウントは「本」の1種類のみですが、棚とテレビと冷蔵庫が地震でズレたり倒れたりすれば3種類としてカウントされ、被害が大きいとみなされるようです。
地震保険の査定額
地震保険は火災保険と違い損害額ではなく、保険金額(契約時に決めている額面)の何割という形で支払われます(地震保険 | 個人のお客さま | AIG損保へのリンク)。
我が家の場合、家財の「一部損」判定でした。この場合、地震保険金額の5%が支払われることになります。契約していた保険金額は100万円くらいだった(それも知らなかった…)ので、支払われる額は大体5万円です。
大阪北部在住で、地震保険に加入している人は、とりあえず被害申請をしてみるといいですね。判定結果が一部損(一番低い)でも、地震でグチャグチャにされた部屋の片づけ手間賃くらいにはなると思います。
査定方法
査定は結構面白いです。馬のフィギュアがテーブルから落ちてたら「被害です」、お皿が落ちたり転げたら割れてなくても「被害です」。逆に言うと、壊れた物の金額は勘案しないので、被害の受け方によっては被害額と保険の査定額が全く合いません。
しかし元々そういう保険なんです。火災保険や自動車保険とは仕組みが違うのですね。
保険会社がんばってる
AIG損害保険の調査員の方曰く、大阪北部地震と7月豪雨の被害調査を迅速に行うため、全国の調査員が応援に駆けつけているのだとか。今日来ていただいた方も北海道から応援に来ていると言っていました。
最近は特に暑いし、特に豪雨の地域では道路がやられていて、被災地を駆け回るにもとても大変らしいです。頭が下がる思いです。
コメント一覧
- コメントはありません。
この記事にコメントする
2018年8月10日
エディタ
誰しもお気に入りのエディタがあると思いますが、私は割とメチャクチャです。
C言語系は読むときはVim + GNU Global、書くときはサクラエディタを使うことが多いです。
Vimはタグジャンプやヒストリが優秀で、検索もしやすいので、コードを読む際にはとても便利だと思います。ログを差し込んだり、コードを多少書き換える程度であればVimで済ませます。
しかし1から全て書くような場合は、サクラエディタが多いです。何ででしょうね?関数表示が便利なのかな?そんなサクラエディタもC++ を書くときはイマイチで、ラムダがまともに表示されず不便です。
GVimでtabと :Tlistを使うとサクラエディタの関数表示に近くて、個人的には良い感じですが、常用には至っていません。何が悪いのかわからない…。
Javaは読むことはあまり無いけどVimですかね、書くときはIntelliJ IDEAです。スクリプト系はVimで読むし、書きます。
こうして並べてみると、かなり支離滅裂です。どうしてこうなった…??
VimとEmacsの思い出
VimもEmacsも初めて使ったとき「は?何だこれ……??」と思いました。どちらも終了方法がわからず、まともに使えませんでした。今はIDEもVimも適度に使っています。
でもEmacsは完全に使い方を忘れてしまった。ごめんねEmacs…。
コメント一覧
- コメントはありません。
この記事にコメントする
2018年8月8日
久しぶりに自作ARMエミュレータ
久しぶりに自作ARMエミュレータememuを(ソースコードはこちら)動かそうと思い、Linux 4.4のlatestである、Linux 4.4.146をダウンロードしました。
このememuではARM Versatile PB/APボードの一部デバイスと、CPU ARM926EJ-Sの一部、アーキテクチャで言えばARMv5T相当をエミュレーションしています。
クロスビルドできない
巷で手に入るコンパイラはARMv5Tより新しい命令を出力してしまい、エミュレータで実行できませんので、最初にcrosstool-ngで、ARMv5T向けのgcc 8.1.0を作成しました。
いざLinux 4.4.146をクロスビルドしましたが、エラーになり、コンパイルできませんでした。
エラーの意味が良く分からなかったので、さっくり諦めましてcrostool-ngでgcc 7.3を作成しなおし、ビルドをやり直したところ、無事コンパイルが通りました。
Linuxが動かない
Linux 4.4.146は起動しませんでした。偶然持っていた少し古いバージョン(Linux 4.4.77)に戻したりもしましたが、結果は同じで全く起動しません。
デバッグすると、ドライバの作りが変わったのかAACIとMMCIというハードウェアに対して、今まで叩いていなかったはずのレジスタをガンガン叩いていました。ememuは存在しないI/Oレジスタを叩くと、エミュレータが例外で落ちてしまい、動かなくなるんです…。
とりあえずレジスタ定義だけ適当に追加したところ、エラーが出まくりますが、起動はしました。適当でも動いてくれるLinuxは強い子です。
buildrootが動かない
しかし今度はbuildrootで作成したbusyboxと愉快な仲間たちが起動しません。/dev/nullが無いよ?と永遠にエラーが出続けます。
調べてみるとLinux 4.4.146のdefconfigだとCONFIG_DEVTMPFSがnつまり無効なんですね。最近の感覚でdevtmpfsはあって当然くらいに思っていたので、盲点でした。コンフィグでdevtmpfsを有効にしてカーネル再ビルドしたところ、やっとbuildrootが動きました。
端末の色がおかしい
対応していない制御文字を送ってきているらしく、ememuの端末(独自実装です)の色がおかしくなります。
これはすぐ直せそうになかったので、しばらくは変な表示と付き合うことになりそうです。
コメント一覧
- すずきさん(2018/08/09 01:09)
後でやりなおしたら gcc 8.1.0 でも Linux 4.4.146 をコンパイルできました。あのエラーは何だったんだろう。幻でも見ていたんだろうか??
この記事にコメントする
2018年8月5日
微妙に壊れてるThinkPad E480のキーボード
先日購入(2018年6月14日の日記参照)したThinkPad E480ですが、キーボードのカーソルキー、しかも上カーソルキーだけが微妙に壊れています。
キーを押すとキーが傾いてしまい、引っかかって戻ってこないときがあります。
キーを分解してみた
何が引っかかっているのか調べるために分解してみました。キートップをてこなどで外すと、パンタグラフが入っています。パンタグラフは2つの部品からできています。

2つの部品を組み合わせると、I字型(畳んでいるとき)もしくはX字型(開いているとき)になります。


良く見るとこの部品、軸が折れてしまっています。

軸が片側なくなっているため、パンタグラフを開いても綺麗なX字型にならず、捻じれてしまいます。

キーボードのパンタグラフ、開いた状態、軸が折れているので歪む
これによってキートップが若干傾いてキーボードのフレームに引っかかり、元の位置に戻らなくなるようです。
対策
修理に出そうかどうか迷って、いろいろ押し方を試しているうちに、比較的引っかかりにくい押し方があることを見つけました。今は押し方を工夫することで凌いでいます。
さらに最近は、普通にキーを押しても引っかかりにくくなった気がします。パンタグラフが壊れているのは相変わらずなので、キートップ側が削れたのか、変形したのかな?
コメント一覧
- コメントはありません。
この記事にコメントする
2018年8月4日
レガシィの4回目の車検
目次: 車
先週、大阪スバル(高槻店)にレガシィの車検をお願いしていました。今日は納車です。
JR高槻駅からディーラーまで歩きましたが、もう、とにかく暑い暑い。暑くてやってられません。将来、車を買い替えるとしたら、夏には絶対、車は買わないぞ、絶対だ。心に決めました。
料金は自賠責&税金込みで13万円くらいでした。特に大きな故障もなかったし、そんなもんでしょう。ね。
コメント一覧
- hdkさん(2018/08/05 01:16)
車検の時はいつも代車借りてます。駅やバス停は近いけど、タダで貸してくれるので... トヨタ系ディーラーだからですかね? でも最初中古車買った店も貸してくれていました。駅から 1km もあるのに代車なしだとつらいですね。 - すずきさん(2018/08/05 01:25)
> hdk さん
スバルも代車を貸してくれますが、今回は長期間(1週間)預けていたことと、8月は休みが多いせいか、単に繁忙期なのか、貸せる代車が無いと言われました…。
この記事にコメントする
| < | 2018 | > | ||||
| << | < | 08 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | 1 | 2 | 3 | 4 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | - |
最近のコメント5件
最近の記事20件
-
 23年5月15日
23年5月15日
すずき (07/03 05:24)
「[車 - まとめリンク] 目次: 車三菱 FTO GPX '95の話。群馬県へのドライブ1群馬県へのドライブ2将来車を買い替え...」 -
26年6月26日
すずき (07/03 05:23)
「[ジャガーさんの不思議なシフト] 目次: 車ジャガーXE(前期型)はシフトがダイヤル型になっていて、P, R, N, D, S...」 -
20年2月22日
すずき (06/26 02:03)
「[Zephyr - まとめリンク] 目次: Zephyr導入、ブート周りHello! Zephyr OS!!Hello! Ze...」 -
26年6月18日
すずき (06/26 02:02)
「[ZephyrのOut-of-treeアプリケーションその6 - シリアル出力] 目次: Zephyr前回はシリアルに文字を出...」 -
26年6月23日
すずき (06/26 01:27)
「[ANA国内線予約サイトが悲惨なことに] 4月くらいにANAの国内線予約サイトが国際線と共通のクラウドシステム(Amadeus...」 -
26年6月11日
すずき (06/26 01:10)
「[ZephyrのOut-of-treeアプリケーションその5 - OpenOCDとGDBで実行] 目次: Zephyr前回Ze...」 -
26年4月29日
すずき (06/24 01:10)
「[ぽこあポケモンをクリア] 目次: ゲーム1日だけやって放置していたぽこあポケモンをクリア(=スタッフロールが流れるイベントを...」 -
26年5月3日
すずき (06/24 01:09)
「[農家はREPLACE()されました、を9割クリア] 目次: ゲーム大昔にちょっとだけやって中断していたゲーム「農家はREPL...」 -
26年5月31日
すずき (06/24 01:08)
「[ZephyrのOut-of-treeアプリケーションその3 - Zephyr SDKのインストール] 目次: Zephyr前...」 -
26年6月8日
すずき (06/23 03:22)
「[ZephyrのOut-of-treeアプリケーションその4 - 最小限のアプリ] 目次: Zephyr便利ツールwestとZ...」 -
26年4月8日
すずき (06/23 03:07)
「[ジャガーさんのエンジンオイル交換、後日談] 目次: 車昨日、ジャガーXEのオイルを交換しました。オートバックスでも家の駐車場...」 -
26年5月28日
すずき (06/23 02:29)
「[ZephyrのOut-of-treeアプリケーションその2 - westの準備] 目次: ZephyrZephyrのアプリケ...」 -
26年5月22日
すずき (06/23 02:20)
「[ZephyrのOut-of-treeアプリケーションその1 - 概要] 目次: ZephyrZephyr RTOSはツリー内...」 -
21年7月10日
すずき (06/02 21:25)
「[OpenOCD - まとめリンク] 目次: OpenOCDOpenOCDとHiFive UnleashedのSPI Flas...」 -
26年6月2日
すずき (06/02 21:25)
「[OpenOCDのビルド2026] 目次: OpenOCD以前(2023年6月28日の日記参照)紹介したときからビルド方法が変...」 -
22年3月18日
すずき (05/28 01:34)
「[射的 - まとめリンク] 目次: 射的ガスガン その1ガスガン その2ガスガンが増えました射的射的2回目射的3回目東京マルイ...」 -
26年5月24日
すずき (05/28 01:34)
「[JTSA Unlimited大会参加2026] 目次: 射的JTSA Unlimitedの大会に参加しました。「水」ステージ...」 -
26年5月16日
すずき (05/21 02:14)
「[「かに」で終わる形容動詞] Xで50音順に「かに」で終わる形容動詞(正確には連用形ですが)を並べている人がいて、面白そうなの...」 -
21年12月28日
すずき (05/06 19:21)
「[ゲーム - まとめリンク] 目次: ゲームNintendo DSを買ったパネルでポンDS最近の朝はパネポンDS聖剣伝説DSチ...」 -
26年4月7日
すずき (04/07 23:02)
「[ジャガーさんのエンジンオイル交換] 目次: 車買ってから6,000kmくらい走ったのでエンジンオイル&オイルフィルターを交換...」
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
