2020年5月16日
GCCを調べる - その10-1 - ベクトル型を使うとエラー(TARGET_VECTOR_MODE_SUPPORTED_P追加編)
目次: GCC
以前(2020年3月27日の日記、2020年3月28日の日記、2020年3月29日の日記参照)ベクトルレジスタを扱えるようにした際に、下記の問題が残っていました。
- 変数がintなのでsizeof(v) が4になる、ベクトルを扱いたい
- 最適化オプションをO0にするとコンパイラがinternal errorを出す
前回(2020年5月12日の日記参照)はベクトル型に向けてマシンモードを追加しました。引き続き、1つ目の問題に取り組んでいきたいと思います。
ベクトル型は基本型(SI, DI, SF, DFなど)が複数連結されているデータ型です。個数は2のべき乗(2, 4, 8, 16, ...)でなければなりません、3個や10個はダメです。型は通常GCCの実装で定義します。ベクトル型も当然同じでGCCの実装で定義しますが、ベクトル型はやや特殊で、GCCのattributeでも定義することができます。今回はattributeを使ってみます。
ベクトル型を使ったコード
typedef int __v64si __attribute__((__vector_size__(256)));
void _start()
{
int b[100];
__v64si v1;
__asm__ volatile ("vlw.v %0, %1\n"
: "=&v"(v1) : "A"(b[10]));
}
ベクトル型を使ってインラインアセンブラを書くとエラーが出ます。
ベクトル型を使うとimpossible constraintエラー
$ riscv32-unknown-elf-gcc -Wall -march=rv32gcv b.c -O2 -nostdlib -S
b.c: In function '_start':
b.c:7:2: error: impossible constraint in 'asm'
7 | __asm__ volatile ("vlw.v %0, %1\n"
| ^~~~~~~
このエラーは以前(2020年3月6日の日記参照)、register constraintに 'v' を追加したときに解析した部分で見ました。詳細は昔の日記を見ていただくとして、以前との差を示します。
エラーになる箇所
// gcc/recog.c
int
asm_operand_ok (rtx op, const char *constraint, const char **constraints)
{
...
default:
cn = lookup_constraint (constraint);
switch (get_constraint_type (cn))
{
case CT_REGISTER:
if (!result
&& reg_class_for_constraint (cn) != NO_REGS //★★以前引っかかっていたのはこちら
&& GET_MODE (op) != BLKmode //★★今回はこちらの条件に引っかかる
&& register_operand (op, VOIDmode))
result = 1;
break;
新たなマシンモードV64SImodeを追加(2020年5月12日の日記参照)を追加したのに、どうしてBLKmodeが選択されてしまうのでしょう?
オプション --dump-tree-all --dump-rtl-allを付けて、BLKmodeが選ばれるタイミングを追うと、パスexpandが終わった時点でBLKmodeになっていました。
236r.expandの抜粋
(insn 26 7 10 2 (set (mem/c:BLK (plus:SI (reg/f:SI 99 virtual-stack-vars) ★★mem/c:BLKになっている
(const_int -1168 [0xfffffffffffffb70])) [1 A128])
(asm_operands/v:BLK ("vlw.v %0, %1") ("=&v") 0 [
(mem/c:SI (plus:SI (reg/f:SI 99 virtual-stack-vars)
(const_int -872 [0xfffffffffffffc98])) [1 b+40 S4 A64])
]
[
(asm_input:SI ("A") b.c:7)
]
[] b.c:7)) "b.c":7:2 -1
(nil))
パスexpandはGIMPLEからRTLという中間表現に変換するパスです。RTLに変換した直後からBLKmodeですから、かなり最初の方からダメだってことがわかります。何が悪いかわからないのでexpand辺りのコードを探ってみます。
BLKmodeになる箇所
// gcc/cfgexpand.c
static void
expand_asm_stmt (gasm *stmt)
{
...
for (i = 0; i < noutputs; ++i)
{
tree val = output_tvec[i];
tree type = TREE_TYPE (val);
bool is_inout, allows_reg, allows_mem, ok;
rtx op;
...
if ((TREE_CODE (val) == INDIRECT_REF && allows_mem)
|| (DECL_P (val)
&& (allows_mem || REG_P (DECL_RTL (val)))
&& ! (REG_P (DECL_RTL (val))
&& GET_MODE (DECL_RTL (val)) != TYPE_MODE (type)))
|| ! allows_reg
|| is_inout
|| TREE_ADDRESSABLE (type))
{
...
}
else
{
op = assign_temp (type, 0, 1); //★★これ
op = validize_mem (op);
if (!MEM_P (op) && TREE_CODE (val) == SSA_NAME)
set_reg_attrs_for_decl_rtl (SSA_NAME_VAR (val), op);
generating_concat_p = old_generating_concat_p;
push_to_sequence2 (after_rtl_seq, after_rtl_end);
expand_assignment (val, make_tree (type, op), false);
after_rtl_seq = get_insns ();
after_rtl_end = get_last_insn ();
end_sequence ();
}
// gcc/function.c
rtx
assign_temp (tree type_or_decl, int memory_required,
int dont_promote ATTRIBUTE_UNUSED)
{
tree type, decl;
machine_mode mode;
#ifdef PROMOTE_MODE
int unsignedp;
#endif
if (DECL_P (type_or_decl))
decl = type_or_decl, type = TREE_TYPE (decl);
else
decl = NULL, type = type_or_decl;
mode = TYPE_MODE (type); //★★これ
// gcc/tree.h
#define TYPE_MODE(NODE) \
(VECTOR_TYPE_P (TYPE_CHECK (NODE)) \
? vector_type_mode (NODE) : (NODE)->type_common.mode) //★★これ
// gcc/tree.c
/* Vector types need to re-check the target flags each time we report
the machine mode. We need to do this because attribute target can
change the result of vector_mode_supported_p and have_regs_of_mode
on a per-function basis. Thus the TYPE_MODE of a VECTOR_TYPE can
change on a per-function basis. */
/* ??? Possibly a better solution is to run through all the types
referenced by a function and re-compute the TYPE_MODE once, rather
than make the TYPE_MODE macro call a function. */
machine_mode
vector_type_mode (const_tree t)
{
machine_mode mode;
gcc_assert (TREE_CODE (t) == VECTOR_TYPE);
mode = t->type_common.mode; //★★このモードはV64SImodeになる
if (VECTOR_MODE_P (mode)
&& (!targetm.vector_mode_supported_p (mode) //★★この判定文が偽になる
|| !have_regs_of_mode[mode]))
{
scalar_int_mode innermode;
/* For integers, try mapping it to a same-sized scalar mode. */
if (is_int_mode (TREE_TYPE (t)->type_common.mode, &innermode)) //★★256バイトのIntはないから、偽になる
{
poly_int64 size = (TYPE_VECTOR_SUBPARTS (t)
* GET_MODE_BITSIZE (innermode));
scalar_int_mode mode;
if (int_mode_for_size (size, 0).exists (&mode)
&& have_regs_of_mode[mode])
return mode;
}
return BLKmode; //★★BLKmodeになってしまう
}
return mode;
}
条件式にあるtargetm.vector_mode_supported_p() がfalseのため、BLKmodeになってしまうようです。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2020年5月13日
ノートPCのファンがうるさい
ノートPC(ThinkPad E480)の冷却ファンが回り続けていてうるさいです。特に何かしている訳でもないのに、良い勢いでファンが回ってます。
ここ最近、ノートPCを酷使(ゲーム、在宅勤務など)したため、ファンに埃が詰まって、冷却能力が下がったか?と予想して、頑張ってThinkPadの裏蓋を開けました。しかし思ったほど汚れていません。
どうしてファンが回りっぱなしなんでしょう?純粋に冷却能力が足りないだけなんだろうか??
ThinkPadの裏蓋
ThinkPad E480の裏蓋はめちゃくちゃ開けにくいです。ネジ9か所と爪で止まっているので、ネジを緩めた後、マイナスドライバーでこじ開けるしかありません。
爪を外すとき、バキっ!ベキっ!というすごい嫌な音がします。案の定、ヒンジ付近(ノートPCとノートPCディスプレイが接続されている方)の爪が4か所ほど折れました。
せっかく裏蓋まで開けたにも関わらず、何も収穫がありませんでした。裏蓋を止める爪が4か所壊れただけです。相変わらずファンはうるせーし、嬉しくない結末です。コメント一覧
- コメントはありません。
この記事にコメントする
2020年5月12日
GCCを調べる - その9 - ベクトル型用マシンモードの追加
目次: GCC
以前(2020年3月27日の日記、2020年3月28日の日記、2020年3月29日の日記参照)ベクトルレジスタを扱えるようにした際に、下記の問題が残っていました。
- 変数がintなのでsizeof(v) が4になる、ベクトルを扱いたい
- 最適化オプションをO0にするとコンパイラがinternal errorを出す
1つ目の問題に取り組んでいきたいと思います。RISC-V 32の場合、intの変数は32bit整数のデータ型として扱われます。GCC内部の表現(RTL)ではSImodeというマシンモード(※)で表されます。他の大きさのデータ型を示すマシンモードも当然存在していて8, 16, 64bit整数はそれぞれBImode, HImode, DImodeで表されます。
普通の型に対応するモードはGCCが定義済みですが、ベクトル型を表すモードは標準では存在しないため、自分で新規に定義する必要があります。
(※)マシンモード(Machine Mode)については、GCC Internalsの14.6 Machine Modesに簡単な説明と標準的なモードの一覧が載っています。これによればSIはSingle Integerの略らしいです。変な名前だなあ。
マシンモードはどこにある?
以前(2020年3月14日の日記参照)説明したとおりですが、軽くおさらいすると、標準的なマシンモードはgcc/machmode.def、アーキテクチャ固有のマシンモードはgcc/config/arch/arch-modes.defにあります。例えばRISC-Vならgcc/config/riscv/riscv-modes.defです。
現在のところRISC-V固有のマシンモードは1つしか定義されていません。
riscv-modes.def
FLOAT_MODE (TF, 16, ieee_quad_format);
このファイルにベクトル型を表すマシンモードを追加します。
riscv-modes.defに追加したモード
VECTOR_MODE (INT, SI, 8);
VECTOR_MODE (INT, SI, 16);
VECTOR_MODE (INT, SI, 32);
VECTOR_MODE (INT, SI, 64);
とりあえず整数(INT, SI)が8, 16, 32, 64(それぞれ32, 64, 128, 256バイト)個連結されているデータ型を想定して作りました。ベクトル型を語る上では浮動小数点型も大事ですが、とりあえず今回は整数型のみを定義しています。
マシンモード追加できたかな
マシンモードを正しく追加できたか確かめる方法は色々あるのでしょうけど、個人的に簡単だと思うのは一旦ビルドしてしまう方法です。
GCCをビルドするとビルド用のディレクトリ(以降build_gccと呼びます)に、モードが全部書いてあるヘッダinsn-modes.hが生成されます。生成されたヘッダを検索すれば一発です。
モードが定義されているヘッダ
// gcc/build_gcc/insn-modes.h
enum machine_mode
{
E_VOIDmode, /* machmode.def:189 */
#define HAVE_VOIDmode
#ifdef USE_ENUM_MODES
#define VOIDmode E_VOIDmode
#else
#define VOIDmode ((void) 0, E_VOIDmode)
#endif
E_BLKmode, /* machmode.def:193 */
#define HAVE_BLKmode
#ifdef USE_ENUM_MODES
#define BLKmode E_BLKmode
#else
#define BLKmode ((void) 0, E_BLKmode)
#endif
...
E_V32SImode, /* config/riscv/riscv-modes.def:26 */
#define HAVE_V32SImode
#ifdef USE_ENUM_MODES
#define V32SImode E_V32SImode
#else
#define V32SImode ((void) 0, E_V32SImode)
#endif
E_V64SImode, /* config/riscv/riscv-modes.def:27 */
#define HAVE_V64SImode
#ifdef USE_ENUM_MODES
#define V64SImode E_V64SImode
#else
#define V64SImode ((void) 0, E_V64SImode)
#endif
...
新たなマシンモードV64SImode(SIが64個連結されたデータ型)が追加されたことがわかると思います。コメントにマシンモードの定義されている場所も書かれていて、とても親切です。
ほぼ全域に渡って意味不明コードだらけのGCCでは珍しい部類の、わかりやすさ&親切さです。自動生成コードには気を使っているんでしょうか?他のところもこれくらい親切だと嬉しいんですけどねえ。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年5月11日
ヤマザキ春のパン祭り
今年のヤマザキ春のパン祭りは、2枚もゲットできました。

去年は品川勤務かつコンビニ昼飯がメインだったので、ヤマザキパンを買う機会がほぼなく、お皿をもらえるほど点がたまりませんでした。今年はCOVID-19による在宅勤務で、近所のスーパーでパンを買う機会が大幅に増えたため、2枚も手に入ったわけです。在宅勤務の意外な効果です。
コンビニに行かない人にとっては意外かもしれませんが、コンビニはヤマザキパンをほとんど置いていません。自社のプライベートブランドのパンばかりです。10年位前は他社のパンも置いていたんですが、今やコンビニは9割方がプライベートブランドのパンです。
コンビニのプライベートブランドのパンは、大手メーカー(ヤマザキパン、敷島製パン、フジパンなど)が作っていますが、コストの都合か何だか知りませんが、味に劣る気がします。好みの問題なのかな……?
強化ガラス
パン祭りのお皿、裏側に何か書いてるなーと思って写真を撮ってみました。

ちょっと見づらいので文字に起こすと、
ARTICLE YAMAZAKI
MADE IN FRANCE
ZENMEN
BUTSURIKYOUKA
GARASU
「全面物理強化ガラス」ってローマ字で書いてありますね。フランス製なのに何でローマ字?フランス語で書かれても読めないから?
見ていて素朴な疑問が沸きました。あえて「全面」と強調する理由はなんでしょうね?皿のように厚みのない製品で「片面」物理強化ガラスにすることは可能?可能だったとしてもやる意味がある?
コメント一覧
- コメントはありません。
この記事にコメントする
2020年5月10日
Pythonの文字置換APIは変な名前
目次: Python
Pythonの文字列置換は "string".replace() ですが、正規表現ライブラリreだと、なぜかre.sub() です。同じ機能なのに、APIの名前も、引数の指定順序も違います。どうしてこうなった。
改定の度に魔界化するC/C++ に比べると、Pythonは明瞭に思えます。とはいえPythonも何だかんだ長い歴史ですし、祓いきれない闇があるんでしょうねえ。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年5月9日
Kindle for PCはダウンロードが遅い?
目次: Kindle
KindleのアプリはKindle Fire版、Android版、PC版など、いくつか種類があります。普段使っているのはKindle FireとKindle for PCです。どうもKindle for PCのダウンロードが遅い気がします。
Kindle Fireも決して速いとは思いませんが、大抵はマンガ1冊が1〜2分でダウンロードできているので、5Mbpsくらいは出ているんじゃないかと思います。
Kindle for PCはかなり遅い(1〜2Mbpsくらい、日によって違う)です。同じネットワークを使っているのに、差が出るものですかね?PC向けだけ帯域ケチるとか、そんな面倒なことしないよなあ?うーん?
Kindleアプリの動きがまた変わったけど、いつもどこかがダメ
Kindle Fire HDのアプリはたまにアップデートされて動きが変わります。今年の頭くらいだったか?覚えてないですけど、また動作が変わりました。
- 良くなったところ
- フィルター「すべて」を選択したとき、本が多すぎると、数十秒フリーズしたり、アプリがクラッシュするバグが直ったこと
- 悪くなったところ
- 本のグループが意図せず表示されてしまうバグが埋め込まれたこと
新たなバグは再現率100%です。再現方法も簡単です。
- ホーム → 「本」のタブ → すべての本を表示、をタップ
- 本の一覧が表示される
- グループ化された本をタップ(マンガの1〜最新巻までをグルーピングする機能)を選択
- ホームボタンでホームへ → 「本」のタブ → すべての本を表示、をタップ
- 先ほど見ていたグループ化された本が表示される(バグ)
この順に操作したとき、本来は本の一覧が出なければなりませんが、グループ化された本が再表示されてしまいます。明らかにバグってます。
このバグは、ユーザー側の操作で回避可能です。
- グループ化された本が意図せず表示される(バグ)
- ホームボタン「ではなく」戻るボタンでホームに戻る
- もう一度、すべての本を表示、をタップ
- 本の一覧が表示される
ユーザーの操作に影響が出るバグですし、テスターに触らせたら数分で見つけそうなのにね?KindleってUIのテストしてないのかなあ??
コメント一覧
- コメントはありません。
この記事にコメントする
2020年5月8日
RISC-Vのgas
目次: RISC-V
マクロの名前にTypoと思しきものがあったので、riscv-binutils-gdb(サイトへのリンク)にPull Requestをしてみました。
RISC-V向けのgasの実装では、命令に対応した名前のマクロがあります。
命令の名前とマクロの名前の関係
//opcodes/riscv-opc.c
//通常は命令の名前からドットを除いて、大文字にした名前
// vadd.vv -> MATCH_VADDVV
{"vadd.vv", 0, INSN_CLASS_V, "Vd,Vt,VsVm", MATCH_VADDVV, MASK_VADDVV, match_opcode, 0 },
{"vadd.vx", 0, INSN_CLASS_V, "Vd,Vt,sVm", MATCH_VADDVX, MASK_VADDVX, match_opcode, 0 },
{"vadd.vi", 0, INSN_CLASS_V, "Vd,Vt,ViVm", MATCH_VADDVI, MASK_VADDVI, match_opcode, 0 },
//Reduce系の命令だけ名前が違う
// vredsum.vs -> MATCH_VREDSUMV"S" のはずなのに、MATCH_VREDSUMV"V" になっている
{"vredsum.vs", 0, INSN_CLASS_V, "Vd,Vt,VsVm", MATCH_VREDSUMVV, MASK_VREDSUMVV, match_opcode, 0},
パッチの中身は簡単で、ベクトル命令の一部で、命令の名前とマクロの名前が違っていたので修正しただけです。この手の間違いがいくつあるか分からなかったので、ちょっとしたPythonスクリプトを書いてチェックしました。
マクロの名前チェックに使ったスクリプト
#!/usr/bin/python
import re
import sys
fname = sys.argv[1]
f = open(fname, 'r')
line = f.readline()
while line:
if not line.startswith('{"'):
line = f.readline()
continue;
line = line.strip().replace('}', '')
line = re.sub('\{"([^,]*)",', r'\1,', line)
line = re.sub('".*",', '', line)
line = re.sub(' *', '', line)
items = line.split(',')
insnOrg = items[0]
insn = items[0].upper()
classInsn = items[2]
matchInsn = items[3]
maskInsn = items[4]
aliasInsn = items[6]
if not classInsn.startswith('INSN_CLASS_V'):
line = f.readline()
continue;
if not matchInsn.startswith('MATCH_') or not maskInsn.startswith('MASK_'):
line = f.readline()
continue;
if aliasInsn.startswith('INSN_ALIAS'):
line = f.readline()
continue;
insn = insn.replace('.', '')
matchInsn = matchInsn.replace('MATCH_', '')
maskInsn = maskInsn.replace('MASK_', '')
if matchInsn != maskInsn:
print("MATCH != MASK: {:s} != {:s}".format(matchInsn, maskInsn))
if insn != matchInsn:
print("INSN != MATCH: {:s} != {:s}".format(insnOrg, matchInsn))
line = f.readline()
条件を適当に継ぎ足して書いたのと、Pythonの経験値が低いのが相まって、エレガントさの欠片もないですね。仕方ない。実行結果はこんな感じです。
マクロの名前チェックに使ったスクリプト
$ ../checker.py opcodes/riscv-opc.c INSN != MATCH: vzext.vf2 != VZEXT_VF2 INSN != MATCH: vsext.vf2 != VSEXT_VF2 INSN != MATCH: vzext.vf4 != VZEXT_VF4 INSN != MATCH: vsext.vf4 != VSEXT_VF4 INSN != MATCH: vzext.vf8 != VZEXT_VF8 INSN != MATCH: vsext.vf8 != VSEXT_VF8 INSN != MATCH: vredsum.vs != VREDSUMVV INSN != MATCH: vredmaxu.vs != VREDMAXUVV INSN != MATCH: vredmax.vs != VREDMAXVV INSN != MATCH: vredminu.vs != VREDMINUVV INSN != MATCH: vredmin.vs != VREDMINVV INSN != MATCH: vredand.vs != VREDANDVV INSN != MATCH: vredor.vs != VREDORVV INSN != MATCH: vredxor.vs != VREDXORVV INSN != MATCH: vwredsumu.vs != VWREDSUMUVV INSN != MATCH: vwredsum.vs != VWREDSUMVV INSN != MATCH: vfredosum.vs != VFREDOSUMV INSN != MATCH: vfredsum.vs != VFREDSUMV INSN != MATCH: vfredmax.vs != VFREDMAXV INSN != MATCH: vfredmin.vs != VFREDMINV INSN != MATCH: vfwredosum.vs != VFWREDOSUMV INSN != MATCH: vfwredsum.vs != VFWREDSUMV INSN != MATCH: vcompress.vm != VCOMPRESSV
明らかにTypoに見えるのはvred/vfred/vcompress系の命令で、vsとvvを取り違えています。
微妙なところなのはvzextです。他はドットを除いた名前なのに、vzextだけドットをアンダースコアに置換した名前です。ルールに一貫性が無いだけか、Typoか、どちらとも言い難いため、今回出したPull Requestでは修正していません。
Pull Request受け付けてるのかな?
リポジトリを見ていてちょっと気になったのはSiFiveの人以外、変更がほとんどないことです。著名プロジェクトでは珍しいです。もしかするとGitHubでPull Requestを受け付けてない(※1)可能性があります。
変更を提案するのはここじゃないとか、そもそも変更は受け付けてませんとか、何でも良いので反応があると嬉しいですね、週明けまで待ちましょうかね……。
(※1)本家および開発の場がGitHub以外に存在していて、GitHubをミラーにしているプロジェクトの場合、GitHub上で何か言っても無視されることがあるようです。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年5月5日
プレーヤー人口が増えるのは良いことだ
Splatoon 2のガチマッチ(Cランク)の難易度が下がった気がします。
1〜2か月前は、20kill対0killで負けたり、1分でノックアウトされたり、超フルボッコで負けまくるのが当たり前で、すっかりやる気がなくなっていましたが、今日久しぶりにやったら一度も負けず、あっさりC+ ランクになりました。
アクションゲームの腕は1か月やそこらで急に上達しないので、私が上達したというよりも、絶対勝てないおかしいレベルのプレーヤーとマッチする割合が減った、そんな感じです。
Stay Homeとかゴールデンウイークとかで、Splatoon 2のプレーヤー人口が盛り返して、初心者クラス(C-〜C+ ランクあたり)に合う人が増えたんじゃないかと推測しています。
最初からこのくらいの難易度だったら、ガチマッチ嫌いにならずに済んだんですけど、すっかりガチマッチ嫌いになってしまった(レギュラーマッチは好き)ので、もう遅いんだよな〜……。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年5月4日
C言語のマクロ
目次: C言語とlibc
C言語のマクロによる置換を、循環参照させたらどうなるでしょう?
循環するマクロ定義
A B C D
#define A B
A B C D
#define B C
A B C D
#define C A
A B C D
結論から言うと問題ありません。下記のような結果になります。
循環するマクロ定義、置換結果
A B C D
B B C D
C C C D
A B C D
4つ目の結果は、置換前のA B C Dと何も変わっていないように見えますが、実はそうではありません。下記のように定義するとわかります。
循環するマクロ定義、マクロによる置換結果を見やすくする
A B C D
#define A 1 B
A B C D
#define B 2 C
A B C D
#define C 3 A
A B C D
循環するマクロ定義、置換結果が見やすいはず
A B C D
1 B B C D
1 2 C 2 C C D
1 2 3 A 2 3 1 B 3 1 2 C D
4つ目の結果の「A」を例にとると、A -> B -> C -> Aと3回のマクロの置換が行われた結果、Aに戻っているわけです。#define A Bのマクロは1度しか適用されないようです。
C言語の仕様
C言語の仕様(C11 final draft (N1570) - 6.10.3.4 Rescanning and further replacementの第2項)を見ると、
2
If the name of the macro being replaced is found during this scan of the replacement list (not including the rest of the source file's preprocessing tokens), it is not replaced. Furthermore, if any nested replacements encounter the name of the macro being replaced, it is not replaced. These nonreplaced macro name preprocessing tokens are no longer available for further replacement even if they are later (re)examined in contexts in which that macro name preprocessing token would otherwise have been replaced.
(直訳)
2
置換されるマクロの名前がreplacement listのスキャン中に見つかった場合(ソースファイルの残りの前処理トークンは含まれません)、そのマクロは置換されません。 さらに、入れ子になった置換が、置換されているマクロの名前に遭遇した場合、それは置換されません。 後にそのマクロ名の前処理トークンが置換されていたであろうコンテキストで(再)検査されても、これらの置換されていないマクロ名の前処理トークンはそれ以上の置換はできなくなります。
正直言って何言ってんだお前……?って感じがしますけども、平たく言うと同じマクロを2回適用しない、ように読めます。
複雑版
下記のように同じマクロで何度も置換できそうなマクロを定義してみます。
循環するマクロ定義、より複雑版
#define A B C
#define B C A
#define C A B
A B C D
循環するマクロ定義、より複雑版、結果
A B A A C A B C B B A B C A C C B C D
1つ1つのトークンがどのマクロで展開されているか図示します。
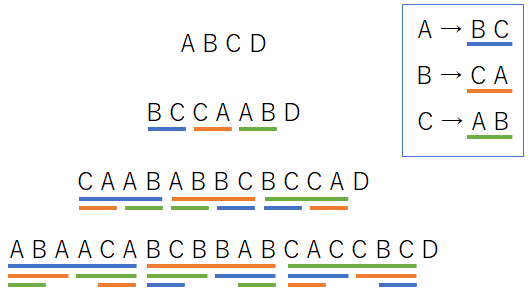
複雑に見えますが、どのトークンを見ても同じマクロを2回適用されたものはないことがわかります。
関数型マクロの謎
しかし関数型マクロの場合は、不思議な挙動を示します。
循環する関数型マクロ定義
#define F(a) a G
#define G(a) a F(a)
F(7)(8)(9)
循環する関数型マクロ定義、結果
7 8 8 G(9)
展開の様子は下記のようになると思われますが、

どうして7 8 8 G(9) で展開が終わるのかが良くわかりません……。マクロF(a) を2回適用しない、というルールならば、7 8 F(8)(9) で止まらなければおかしいように思いますが、結果を見るとなぜかF(8) も展開されています。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2020 | > | ||||
| << | < | 05 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | - | - | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 | - | - | - | - | - | - |
最近のコメント5件
最近の記事20件
-
 23年5月15日
23年5月15日
すずき (07/03 05:24)
「[車 - まとめリンク] 目次: 車三菱 FTO GPX '95の話。群馬県へのドライブ1群馬県へのドライブ2将来車を買い替え...」 -
26年6月26日
すずき (07/03 05:23)
「[ジャガーさんの不思議なシフト] 目次: 車ジャガーXE(前期型)はシフトがダイヤル型になっていて、P, R, N, D, S...」 -
20年2月22日
すずき (06/26 02:03)
「[Zephyr - まとめリンク] 目次: Zephyr導入、ブート周りHello! Zephyr OS!!Hello! Ze...」 -
26年6月18日
すずき (06/26 02:02)
「[ZephyrのOut-of-treeアプリケーションその6 - シリアル出力] 目次: Zephyr前回はシリアルに文字を出...」 -
26年6月23日
すずき (06/26 01:27)
「[ANA国内線予約サイトが悲惨なことに] 4月くらいにANAの国内線予約サイトが国際線と共通のクラウドシステム(Amadeus...」 -
26年6月11日
すずき (06/26 01:10)
「[ZephyrのOut-of-treeアプリケーションその5 - OpenOCDとGDBで実行] 目次: Zephyr前回Ze...」 -
26年4月29日
すずき (06/24 01:10)
「[ぽこあポケモンをクリア] 目次: ゲーム1日だけやって放置していたぽこあポケモンをクリア(=スタッフロールが流れるイベントを...」 -
26年5月3日
すずき (06/24 01:09)
「[農家はREPLACE()されました、を9割クリア] 目次: ゲーム大昔にちょっとだけやって中断していたゲーム「農家はREPL...」 -
26年5月31日
すずき (06/24 01:08)
「[ZephyrのOut-of-treeアプリケーションその3 - Zephyr SDKのインストール] 目次: Zephyr前...」 -
26年6月8日
すずき (06/23 03:22)
「[ZephyrのOut-of-treeアプリケーションその4 - 最小限のアプリ] 目次: Zephyr便利ツールwestとZ...」 -
26年4月8日
すずき (06/23 03:07)
「[ジャガーさんのエンジンオイル交換、後日談] 目次: 車昨日、ジャガーXEのオイルを交換しました。オートバックスでも家の駐車場...」 -
26年5月28日
すずき (06/23 02:29)
「[ZephyrのOut-of-treeアプリケーションその2 - westの準備] 目次: ZephyrZephyrのアプリケ...」 -
26年5月22日
すずき (06/23 02:20)
「[ZephyrのOut-of-treeアプリケーションその1 - 概要] 目次: ZephyrZephyr RTOSはツリー内...」 -
21年7月10日
すずき (06/02 21:25)
「[OpenOCD - まとめリンク] 目次: OpenOCDOpenOCDとHiFive UnleashedのSPI Flas...」 -
26年6月2日
すずき (06/02 21:25)
「[OpenOCDのビルド2026] 目次: OpenOCD以前(2023年6月28日の日記参照)紹介したときからビルド方法が変...」 -
22年3月18日
すずき (05/28 01:34)
「[射的 - まとめリンク] 目次: 射的ガスガン その1ガスガン その2ガスガンが増えました射的射的2回目射的3回目東京マルイ...」 -
26年5月24日
すずき (05/28 01:34)
「[JTSA Unlimited大会参加2026] 目次: 射的JTSA Unlimitedの大会に参加しました。「水」ステージ...」 -
26年5月16日
すずき (05/21 02:14)
「[「かに」で終わる形容動詞] Xで50音順に「かに」で終わる形容動詞(正確には連用形ですが)を並べている人がいて、面白そうなの...」 -
21年12月28日
すずき (05/06 19:21)
「[ゲーム - まとめリンク] 目次: ゲームNintendo DSを買ったパネルでポンDS最近の朝はパネポンDS聖剣伝説DSチ...」 -
26年4月7日
すずき (04/07 23:02)
「[ジャガーさんのエンジンオイル交換] 目次: 車買ってから6,000kmくらい走ったのでエンジンオイル&オイルフィルターを交換...」
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
