2024年11月20日
nvJPEGとNVJPGとJetson APIその2 - nvJPEG simple decode API
目次: Linux
半年経ったら完全に忘れるのでメモします。最近JPEGのデコードエンコードが必要になって色々調べていました。NVIDIA GPUとCUDAを使ってJPEGが扱えるそうで、API名はnvJPEGだそうです(nvJPEGのAPIドキュメント)。
nvJPEG simple decoding
前回ご紹介したdecoupled decodingは呼び出すべきAPI数が多くて、ウワァ……と引いてしまう見た目でした。今回のsimple decodingはその名の通りシンプルです。ちなみにエンコード側もあります。なぜかsimpleに該当するAPIしかなく、decoupled相当のエンコード用APIは存在しないようです。変なの。
Simple decodingはこんな感じでした。Decoupledと比べるとかなりAPIが少なく済みます。
nvJPEG simple decodingのAPI呼び出し順
cudaStream_t stream = nullptr;
nvjpegHandle_t nvj_handle = nullptr;
nvjpegJpegState_t nvj_state = nullptr;
nvjpegImage_t outbuf = {0};
uint8_t *img_buf[4] = {nullptr};
int img_stride[4] = {0};
int img_sz[4] = {0};
int r;
// Create
cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking);
nvjpegCreateEx(NVJPEG_BACKEND_DEFAULT, nullptr, nullptr, NVJPEG_FLAGS_DEFAULT, &nvj_handle);
nvjpegJpegStateCreate(nvj_handle, &nvj_state);
//2のべき乗境界に切り上げる
#define ALIGN_2N(a, b) (((a) + (b) - 1) & ~((b) - 1))
outbuf.pitch[0] = ALIGN_2N(width, 256);
outbuf.pitch[1] = ALIGN_2N(width, 256);
outbuf.pitch[2] = ALIGN_2N(width, 256);
cudaMalloc(&outbuf.channel[0], outbuf.pitch[0] * height);
cudaMalloc(&outbuf.channel[1], outbuf.pitch[1] * height);
cudaMalloc(&outbuf.channel[2], outbuf.pitch[2] * height);
img_stride[0] = ALIGN_2N(width, 256);
img_stride[1] = ALIGN_2N(width, 256);
img_stride[2] = ALIGN_2N(width, 256);
img_buf[0] = (uint8_t *)malloc(img_stride[0] * height);
img_buf[1] = (uint8_t *)malloc(img_stride[1] * height);
img_buf[2] = (uint8_t *)malloc(img_stride[2] * height);
//Decoupled phase decoding
nvjpegGetImageInfo(nvj_handle, jpegbuf, jpegsize, &jpegcomps, &jpegsamp, jpegwidths, jpegheights);
nvjpegDecode(nvj_handle, nvj_state, jpegbuf, jpegsize, NVJPEG_OUTPUT_YUV, &outbuf, stream);
cudaStreamSynchronize(stream);
for (int i = 0; i < 3; i++) {
cudaMemcpy2D(img_buf[i], img_stride[i], outbuf.channel[i], outbuf.pitch[i],
width, height, cudaMemcpyDeviceToHost);
}
// Destroy
free(img_buf[0]);
free(img_buf[1]);
free(img_buf[2]);
cudaFree(outbuf.channel[0]);
cudaFree(outbuf.channel[1]);
cudaFree(outbuf.channel[2]);
nvjpegJpegStateDestroy(nvj_state);
nvjpegDestroy(nvj_handle);
cudaStreamDestroy(stream);
1枚だけJPEGをデコードするならこちらの方が断然楽ですね。
実行
前回同様にソースコードを置いておきます。
 nvJPEG simple decoding
nvJPEG simple decoding使い方はコードの先頭にコメントで書いている通りですが、ここでも説明しておきます。引数はありません。ファイル名test_420.jpgのJPEGファイルを読み込んで、ファイル名simple_420.yuvのRawvideoファイルを書き出します。
コンパイル、結果確認
$ g++ -g -O2 -Wall 20241120_nvjpeg_simple_dec.cpp -lnvjpeg -lcudart $ ./a.out $ ffplay -f rawvideo -video_size 1920x1440 -pixel_format yuv420p -i simple_420.yuv
デコード結果のRawvideoを確認するときはffplayを使うと便利です。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2024年11月18日
nvJPEGとNVJPGとJetson APIその1 - nvJPEG decoupled API
目次: Linux
半年経ったら完全に忘れるのでメモします。最近JPEGのデコードエンコードが必要になって色々調べていました。NVIDIA GPUとCUDAを使ってJPEGが扱えるそうで、API名はnvJPEGだそうです(nvJPEGのAPIドキュメント)。それと別にJPEGのHWコーデックもあり、名前はNVJPG(Eがない)です。nvJPEGと紛らわしくて仕方ありません。
nvJPEG decoupled decoding
NVIDIAがnvJPEGのサンプルを公開しています(nvJPEGデコードサンプルコード)。ありがたいですね。でもなぜかサンプルはデコーダーしかありません。一応Resizeサンプルでエンコーダーを扱っていますが、なぜこんなサンプルの構造にしたのでしょう。
エンコード方法は公式ドキュメント(nvJPEGのドキュメント)の3.1.5 JPEG Encoding Exampleがシンプルで見やすいかもしれません。こちらはなぜかデコーダーのサンプルがありません。変なの。
困ったことにデコーダーのサンプルはRGBからYUVに変更すると動きません。試行錯誤したところストライドが間違っているようです。あとYUV420P(UとVプレーンの幅と高さはYプレーンの半分)なのに、YとUVが同じ高さじゃないとお気に召さないようでした。すなわち、
- ストライドを256バイトの倍数にする
- YUVの3プレーン全ての高さを同じにする
このようにするとデコードできました。ドキュメントに何も書いていないので、バグか合っているか全くわかりません。上記を考慮しつつDecoupled decodingする場合のAPI呼び出し順を載せておきます。
CUDA関連の謎APIについては、CUDA Stream Management(cudaStream_tなどのドキュメント)と、CUDA Memory Management(cudaMalloc()などのドキュメント)をご参照ください。
nvJPEG decoupled decodingのAPI呼び出し順
cudaStream_t stream = nullptr;
nvjpegHandle_t nvj_handle = nullptr;
nvjpegJpegState_t nvj_dcstate = nullptr;
nvjpegBufferPinned_t pinned_buffers[2] = {nullptr};
nvjpegBufferDevice_t device_buffer = nullptr;
nvjpegJpegStream_t jpeg_streams[2] = {nullptr};
nvjpegDecodeParams_t nvj_decparams = nullptr;
nvjpegJpegDecoder_t nvj_dec = nullptr;
nvjpegImage_t outbuf = {0};
uint8_t *img_buf[4] = {nullptr};
int img_stride[4] = {0};
int img_sz[4] = {0};
int r;
// Create
cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking);
nvjpegCreateEx(NVJPEG_BACKEND_DEFAULT, nullptr, nullptr, NVJPEG_FLAGS_DEFAULT, &nvj_handle);
nvjpegDecoderCreate(nvj_handle, NVJPEG_BACKEND_DEFAULT, &nvj_dec);
nvjpegDecoderStateCreate(nvj_handle, nvj_dec, &nvj_dcstate);
nvjpegBufferPinnedCreate(nvj_handle, nullptr, &pinned_buffers[0]);
nvjpegBufferPinnedCreate(nvj_handle, nullptr, &pinned_buffers[1]);
nvjpegBufferDeviceCreate(nvj_handle, nullptr, &device_buffer);
nvjpegJpegStreamCreate(nvj_handle, &jpeg_streams[0]);
nvjpegJpegStreamCreate(nvj_handle, &jpeg_streams[1]);
nvjpegDecodeParamsCreate(nvj_handle, &nvj_decparams);
//2のべき乗境界に切り上げる
#define ALIGN_2N(a, b) (((a) + (b) - 1) & ~((b) - 1))
outbuf.pitch[0] = ALIGN_2N(width, 256);
outbuf.pitch[1] = ALIGN_2N(width, 256);
outbuf.pitch[2] = ALIGN_2N(width, 256);
cudaMalloc(&outbuf.channel[0], outbuf.pitch[0] * height);
cudaMalloc(&outbuf.channel[1], outbuf.pitch[1] * height);
cudaMalloc(&outbuf.channel[2], outbuf.pitch[2] * height);
img_stride[0] = width;
img_stride[1] = width / 2;
img_stride[2] = width / 2;
img_sz[0] = img_stride[0] * height;
img_sz[1] = img_stride[1] * height / 2;
img_sz[2] = img_stride[2] * height / 2;
img_buf[0] = (uint8_t *)malloc(img_sz[0]);
img_buf[1] = (uint8_t *)malloc(img_sz[1]);
img_buf[2] = (uint8_t *)malloc(img_sz[2]);
//Decoupled phase decoding
nvjpegStateAttachDeviceBuffer(nvj_dcstate, device_buffer);
nvjpegOutputFormat_t fmt = NVJPEG_OUTPUT_YUV;
nvjpegDecodeParamsSetOutputFormat(nvj_decparams, fmt);
int index = 0;
nvjpegJpegStreamParse(nvj_handle, jpegbuf, jpegsize, 0, 0, jpeg_streams[index]);
nvjpegStateAttachPinnedBuffer(nvj_dcstate, pinned_buffers[index]);
nvjpegDecodeJpegHost(nvj_handle, nvj_dec, nvj_dcstate, nvj_decparams, jpeg_streams[index]);
nvjpegDecodeJpegTransferToDevice(nvj_handle, nvj_dec, nvj_dcstate, jpeg_streams[index], stream);
nvjpegDecodeJpegDevice(nvj_handle, nvj_dec, nvj_dcstate, &outbuf, stream);
cudaStreamSynchronize(stream);
for (int i = 0; i < 3; i++) {
cudaMemcpy2D(img_buf[i], img_stride[i], outbuf.channel[i], outbuf.pitch[i],
(i == 0) ? width : width / 2,
(i == 0) ? height : height / 2,
cudaMemcpyDeviceToHost);
}
// Destroy
free(img_buf[0]);
free(img_buf[1]);
free(img_buf[2]);
cudaFree(outbuf.channel[0]);
cudaFree(outbuf.channel[1]);
cudaFree(outbuf.channel[2]);
nvjpegDecodeParamsDestroy(nvj_decparams);
nvjpegJpegStreamDestroy(jpeg_streams[0]);
nvjpegJpegStreamDestroy(jpeg_streams[1]);
nvjpegBufferPinnedDestroy(pinned_buffers[0]);
nvjpegBufferPinnedDestroy(pinned_buffers[1]);
nvjpegBufferDeviceDestroy(device_buffer);
nvjpegJpegStateDestroy(nvj_dcstate);
nvjpegDecoderDestroy(nvj_dec);
nvjpegDestroy(nvj_handle);
cudaStreamDestroy(stream);
今回紹介したdecoupled decodingは速度が稼げるみたいですが、複雑です。もっと簡単なsimple decodingもあるので次回にご紹介しようと思います。
実行
ソースコードも置いておきます。
使い方はコードの先頭にコメントで書いている通りですが、ここでも説明しておきます。引数はありません。ファイル名test_420.jpgのJPEGファイルを読み込んで、ファイル名decoupled_420.yuvのRawvideoファイルを書き出します。
コンパイル、結果確認
$ g++ -g -O2 -Wall 20241118_nvjpeg_decoupled.cpp -lnvjpeg -lcudart $ ./a.out $ ffplay -f rawvideo -video_size 1920x1440 -pixel_format yuv420p -i decoupled_420.yuv
Rawvideoを確認するときはffplayを使うと便利です。FFMPEGは本当にありがたい。
コメント一覧
- コメントはありません。
この記事にコメントする
2024年11月17日
JTSA Limited大会参加2024
目次: 射的
JTSA Limitedの大会に参加しました。去年はベレッタが壊れましたが、今年は大丈夫でした。記録は絶好調というほどではありませんでしたが、自己ベストに近い71.65秒のタイムが出ました(総合79位/115人、LM 16位/26人)。さすがに3年目ともなると大会本番のまぐれ当たり&自己ベスト、なんて嬉しいアクシデントは発生しませんでした。
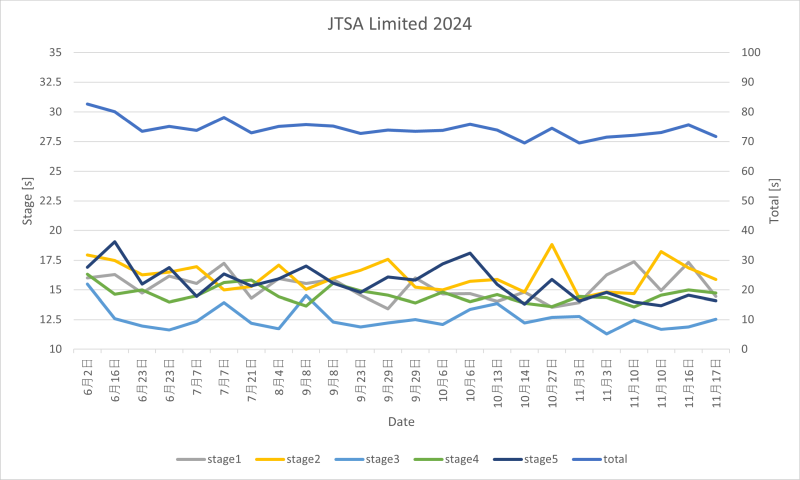
大会の記録だけ見ると、2022年85秒、2023年76秒、2024年71秒と順調に記録は伸びています。良きかな良きかな。来年はどうなるかな?
コメント一覧
- コメントはありません。
この記事にコメントする
2024年11月11日
Pythonのテストフレームワーク
目次: Python
最近Pythonを触ることが増えたのでテストについて調べようと思い立ちました。超有名テストフレームワークpytestがありますので、無から使い始めるまでを試します。
環境はDebian Testingで、ツールのバージョンはpython 3.12.6, pytest 8.2.2です。
設定ファイルは新し目のpyproject.tomlにします。その他の選択肢についてはpytestのドキュメントを参照ください。設定ファイルではpytest実行時のオプション、テスト用のスクリプトが置いてあるディレクトリを指定します。
pytestの設定
# pyproject.toml
[tool.pytest.ini_options]
minversion = "6.0"
addopts = "-ra -q"
testpaths = [
"tests",
]
サンプルにあるオプションの説明をしておくと、
- -ra: パスしなかった結果だけレポートする
- -q: バージョン情報などのメッセージを抑制する
となります。これらの効果を打ち消したければ、
- -rA: 全ての結果をレポートする
- -vまたは-vv: メッセージ全て(-vvだとより大量に)表示する
オプションを使うと良いみたいです。
テスト対象を作成する
全体構造はこんな感じです。
ディレクトリとファイル構造
.
|-- pyproject.toml
|-- sample
| `-- main.py
`-- tests
|-- __init__.py ★★空っぽでOK★★
`-- test_main.py
テストするにはテスト対象のコードが必要です。とりあえず成功と失敗を見たいので、合っている関数と間違っている関数の2つを作りました。アホみたいなコードですけど気にしないでください。
テスト対象のコード
# sample/main.py
def my_add(a, b):
print('my_add!!!!')
return a + b
def my_wrong_add(a, b):
print('my_wrong_add!!!!')
return a + b + 1
テストするためのコードは下記のとおりです。クラスを作ってその下にメソッドを足していくのが基本的な使い方です。
テストのコード
# tests/test_main.py
import pytest
from sample.main import my_add, my_wrong_add
class TestAdd:
def test_add(self):
assert my_add(1, 2) == 3
def test_wrong_add(self):
assert my_wrong_add(1, 2) == 3
クラスに分ける理由が良くわからなかったのですが、世の中のテスト達を見ているとどうもクラスごとにmarkを付けて、Linuxだったら実行する、Macだったら実行するなどの条件を追加する単位として使うようです。
テストの実行
実行は簡単でpytestコマンドを実行するだけです。
成功と失敗が発生する実行結果
$ pytest
.F [100%]
=================================== FAILURES ===================================
____________________________ TestAdd.test_wrong_add ____________________________
self = <tests.test_main.TestAdd object at 0x7f617eab4650>
def test_wrong_add(self):
> assert my_wrong_add(1, 2) == 3
E assert 4 == 3
E + where 4 = my_wrong_add(1, 2)
tests/test_main.py:9: AssertionError
----------------------------- Captured stdout call -----------------------------
my_wrong_add!!!!
=========================== short test summary info ============================
FAILED tests/test_main.py::TestAdd::test_wrong_add - assert 4 == 3
1 failed, 1 passed in 0.03s
関数my_add()のテストは成功し、my_wrong_add()のテストは失敗します。意図通りですね。my_wrong_add()を修正すればテスト成功する様子も簡単に確認できるはずです。
全て成功する実行結果
$ pytest .. [100%] 2 passed in 0.00s
テストはスクリプト、テストクラス、関数を指定して部分的に実行できます。
部分的にテストを実行する方法
#### スクリプトを指定 $ pytest tests/test_main.py .. [100%] 2 passed in 0.00s #### クラスを指定 $ pytest tests/test_main.py::TestAdd .. [100%] 2 passed in 0.00s #### 関数を指定 $ pytest tests/test_main.py::TestAdd::test_add . [100%] 1 passed in 0.00s
失敗するテストだけ何度も再実行するときに便利ですね。
テストが出力した結果はどこへ?
どちらの関数もprint()しますが、失敗したテストの標準出力のみが表示され、成功したテストの標準出力は無視されます。もし成功したテストも見たければ-rAを指定してください。
成功するテストの標準出力も表示する
$ pytest -rA .. [100%] ==================================== PASSES ==================================== _______________________________ TestAdd.test_add _______________________________ ----------------------------- Captured stdout call ----------------------------- my_add!!!! ____________________________ TestAdd.test_wrong_add ____________________________ ----------------------------- Captured stdout call ----------------------------- my_wrong_add!!!! =========================== short test summary info ============================ PASSED tests/test_main.py::TestAdd::test_add PASSED tests/test_main.py::TestAdd::test_wrong_add 2 passed in 0.00s
とりあえず基本的な使い方はこんなもんかなと思います。また気が向いたら書きます。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2024 | > | ||||
| << | < | 11 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | - | - | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
最近のコメント5件
最近の記事20件
-
 23年5月15日
23年5月15日
すずき (07/22 03:04)
「[車 - まとめリンク] 目次: 車三菱 FTO GPX '95の話。群馬県へのドライブ1群馬県へのドライブ2将来車を買い替え...」 -
26年7月22日
すずき (07/22 03:04)
「[ジャガーさんの冷却水漏れの修理見積もり] 目次: 車先週、冷却水がほぼなくなってしまい修理工場にレッカーしたジャガーさんです...」 -
26年7月14日
すずき (07/22 02:37)
「[ジャガーさんの冷却水漏れ] 目次: 車朝、出勤しようと思ってエンジンをかけたところ冷却水不足と表示されました。わぁ、ついに出...」 -
26年7月19日
すずき (07/20 04:04)
「[ゲームを買ったら遊びましょう4] 目次: ゲーム前回の振り返り(2025年12月22日の日記参照)から半年経ちました。Swi...」 -
21年12月28日
すずき (07/20 04:03)
「[ゲーム - まとめリンク] 目次: ゲームNintendo DSを買ったパネルでポンDS最近の朝はパネポンDS聖剣伝説DSチ...」 -
26年7月13日
すずき (07/19 23:33)
「[Flightradar24のcontributorになる方法] 目次: 自宅サーバーADS-Bを受信できる環境があればFli...」 -
23年6月1日
すずき (07/19 23:31)
「[自宅サーバー - まとめリンク] 目次: 自宅サーバーこの日記システム、Wikiの話。カウンターをPerlからPHPに移植日...」 -
23年9月11日
すずき (07/15 12:18)
「[Windows - まとめリンク] 目次: WindowsWindows XPのブリッジ機能colinuxとWindowsの...」 -
25年1月31日
すずき (07/15 12:18)
「[Windowsの日本語フォントはみな長生き] 目次: WindowsGNOME48からフォントが変わるニュースを見ていて、フ...」 -
26年7月11日
すずき (07/12 01:26)
「[Timberborn、トロフィーコンプ] 目次: ゲームTimberbornのトロフィーをコンプリートしました。アーリーアク...」 -
24年2月7日
すずき (07/11 13:05)
「[複数の音声ファイルのラウドネスを統一したい] 目次: PythonPCやデジタル音楽プレーヤーで音楽を聞いていると、曲によっ...」 -
26年6月27日
すずき (07/08 01:45)
「[ジャガーさんのバンパー修理] 目次: 車以前(2025年11月21日の日記参照)、ジャガーさんの左前をぶつけてバンパーをガリ...」 -
26年7月3日
すずき (07/08 00:42)
「[ADS-Bを受信して飛行機の位置を見よう] 目次: 自宅サーバー空を飛ぶ飛行機は離陸直後や着陸寸前でもない限り飛んでいる姿は...」 -
26年7月1日
すずき (07/04 02:37)
「[GPSは世界一正確な時計、その3 - ntpsecとgpsd] 目次: 自宅サーバー以前(2015年5月8日の日記参照)、G...」 -
26年6月26日
すずき (07/03 05:23)
「[ジャガーさんの不思議なシフト] 目次: 車ジャガーXE(前期型)はシフトがダイヤル型になっていて、P, R, N, D, S...」 -
20年2月22日
すずき (06/26 02:03)
「[Zephyr - まとめリンク] 目次: Zephyr導入、ブート周りHello! Zephyr OS!!Hello! Ze...」 -
26年6月18日
すずき (06/26 02:02)
「[ZephyrのOut-of-treeアプリケーションその6 - シリアル出力] 目次: Zephyr前回はシリアルに文字を出...」 -
26年6月23日
すずき (06/26 01:27)
「[ANA国内線予約サイトが悲惨なことに] 4月くらいにANAの国内線予約サイトが国際線と共通のクラウドシステム(Amadeus...」 -
26年6月11日
すずき (06/26 01:10)
「[ZephyrのOut-of-treeアプリケーションその5 - OpenOCDとGDBで実行] 目次: Zephyr前回Ze...」 -
26年4月29日
すずき (06/24 01:10)
「[ぽこあポケモンをクリア] 目次: ゲーム1日だけやって放置していたぽこあポケモンをクリア(=スタッフロールが流れるイベントを...」
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
