 未来から過去へ表示(*)
未来から過去へ表示(*) 2019年12月14日
memsetのベンチマーク(x86_64, Ryzen 7 2700編)
目次: ベンチマーク
(参考)コード一式はGitHubに置きました(GitHubへのリンク)
昨日musl C libraryのmemset関数を調べていたときに「単純な実装と比較して、どれくらい速いんだろうか?」と疑問に思いました。単純な実装とは下記のような実装です。
単純なmemset実装
void *memset_simple(void *dest, int c, size_t n)
{
unsigned char *s = dest;
for (; n; n--, s++) *s = c;
return dest;
}
Cライブラリは世の中にたくさん実装がありますが、glibc-2.28とmusl-1.1.24にご登場願うことにします。各Cライブラリのmemset実装は下記のとおりです。
GNU C libraryのmemset実装(C言語版)
void *memset_glibc(void *dstpp, int c, size_t len)
{
long int dstp = (long int) dstpp;
if (len >= 8)
{
size_t xlen;
op_t cccc;
cccc = (unsigned char) c;
cccc |= cccc << 8;
cccc |= cccc << 16;
if (OPSIZ > 4)
/* Do the shift in two steps to avoid warning if long has 32 bits. */
cccc |= (cccc << 16) << 16;
/* There are at least some bytes to set.
No need to test for LEN == 0 in this alignment loop. */
while (dstp % OPSIZ != 0)
{
((byte *) dstp)[0] = c;
dstp += 1;
len -= 1;
}
/* Write 8 `op_t' per iteration until less than 8 `op_t' remain. */
xlen = len / (OPSIZ * 8);
while (xlen > 0)
{
((op_t *) dstp)[0] = cccc;
((op_t *) dstp)[1] = cccc;
((op_t *) dstp)[2] = cccc;
((op_t *) dstp)[3] = cccc;
((op_t *) dstp)[4] = cccc;
((op_t *) dstp)[5] = cccc;
((op_t *) dstp)[6] = cccc;
((op_t *) dstp)[7] = cccc;
dstp += 8 * OPSIZ;
xlen -= 1;
}
len %= OPSIZ * 8;
/* Write 1 `op_t' per iteration until less than OPSIZ bytes remain. */
xlen = len / OPSIZ;
while (xlen > 0)
{
((op_t *) dstp)[0] = cccc;
dstp += OPSIZ;
xlen -= 1;
}
len %= OPSIZ;
}
/* Write the last few bytes. */
while (len > 0)
{
((byte *) dstp)[0] = c;
dstp += 1;
len -= 1;
}
return dstpp;
}
musl C libraryのmemset実装(C言語版)
void *memset_musl(void *dest, int c, size_t n)
{
unsigned char *s = dest;
size_t k;
/* Fill head and tail with minimal branching. Each
* conditional ensures that all the subsequently used
* offsets are well-defined and in the dest region. */
if (!n) return dest;
s[0] = c;
s[n-1] = c;
if (n <= 2) return dest;
s[1] = c;
s[2] = c;
s[n-2] = c;
s[n-3] = c;
if (n <= 6) return dest;
s[3] = c;
s[n-4] = c;
if (n <= 8) return dest;
/* Advance pointer to align it at a 4-byte boundary,
* and truncate n to a multiple of 4. The previous code
* already took care of any head/tail that get cut off
* by the alignment. */
k = -(uintptr_t)s & 3;
s += k;
n -= k;
n &= -4;
#ifdef __GNUC__
typedef uint32_t __attribute__((__may_alias__)) u32;
typedef uint64_t __attribute__((__may_alias__)) u64;
u32 c32 = ((u32)-1)/255 * (unsigned char)c;
/* In preparation to copy 32 bytes at a time, aligned on
* an 8-byte bounary, fill head/tail up to 28 bytes each.
* As in the initial byte-based head/tail fill, each
* conditional below ensures that the subsequent offsets
* are valid (e.g. !(n<=24) implies n>=28). */
*(u32 *)(s+0) = c32;
*(u32 *)(s+n-4) = c32;
if (n <= 8) return dest;
*(u32 *)(s+4) = c32;
*(u32 *)(s+8) = c32;
*(u32 *)(s+n-12) = c32;
*(u32 *)(s+n-8) = c32;
if (n <= 24) return dest;
*(u32 *)(s+12) = c32;
*(u32 *)(s+16) = c32;
*(u32 *)(s+20) = c32;
*(u32 *)(s+24) = c32;
*(u32 *)(s+n-28) = c32;
*(u32 *)(s+n-24) = c32;
*(u32 *)(s+n-20) = c32;
*(u32 *)(s+n-16) = c32;
/* Align to a multiple of 8 so we can fill 64 bits at a time,
* and avoid writing the same bytes twice as much as is
* practical without introducing additional branching. */
k = 24 + ((uintptr_t)s & 4);
s += k;
n -= k;
/* If this loop is reached, 28 tail bytes have already been
* filled, so any remainder when n drops below 32 can be
* safely ignored. */
u64 c64 = c32 | ((u64)c32 << 32);
for (; n >= 32; n-=32, s+=32) {
*(u64 *)(s+0) = c64;
*(u64 *)(s+8) = c64;
*(u64 *)(s+16) = c64;
*(u64 *)(s+24) = c64;
}
#else
/* Pure C fallback with no aliasing violations. */
for (; n; n--, s++) *s = c;
#endif
return dest;
}
単純な実装と比較して、かなり長いですし、分岐を減らす、アラインメントを取る、一度に複数バイト(8, 16バイトなど)コピーするなど、各所に工夫が見られます。
測定条件、測定対象
動作環境は、
- CPU: AMD Ryzen 7 2700
- Mem: DDR4-2400 (Dual Channel), 32GB (8GB x 4)
- OS: Debian GNU/Linux 11 (bullseye)
- gcc: gcc (Debian 9.2.1-21) 9.2.1 20191130
- Linux: 5.2.0-3-amd64 #1 SMP Debian 5.2.17-1 (2019-09-26) x86_64 GNU/Linux
単純なmemsetと、glibcのmemsetと、muslのmemsetの3つとの比較対象として、普通にmemsetを呼んだ場合の速度を用います。実体はglibcのSSE2版memset実装(アセンブラで実装されている)が呼び出されます。この関数を使う理由は下記の通りです。
- 領域のサイズに反比例した、綺麗なカーブを描くので、基準として見やすい
- アセンブラ実装なので、コンパイラの最適化レベルの影響をほとんど受けず、性能が一定
測定方法ですが、1バイトのmemsetを10億回、2バイトのmemsetを5億回、……のように、一度に処理する領域を増やしながら、処理回数を減らします。合計でおよそ1GBの領域をmemsetするようにしています。
コンパイラの最適化と公平な比較
ベンチマークに使う呼び出し側プログラムは下記のように、関数ポインタ経由で呼び出し、コンパイル時に -fno-builtinオプションをつけます。
ベンチマーク測定用のプログラム(一部)
char tmpbuf[1024 * 1024 * 1024];
struct testcase cases[] = {
{ "libc", memset, },
{ "glibc avx2", __memset_avx2_unaligned, },
{ "musl asm", memset_musl_asm, },
{ "glibc C", memset_glibc, },
{ "musl C", memset_musl, },
{ "simple", memset_simple, },
{ "size", 0, },
{ "cnt", 0, },
{ 0, 0, },
};
void test(char *p, size_t size, int cnt)
{
int pos, i;
for (pos = 0; cases[pos].func; pos++) {
gettimeofday(&cases[pos].start.tv, NULL);
for (i = 0; i < cnt; i++) {
cases[pos].func(p, i, size);
}
gettimeofday(&cases[pos].end.tv, NULL);
}
cases[pos].start.n = 0;
cases[pos].end.n = size;
pos++;
cases[pos].start.n = 0;
cases[pos].end.n = cnt;
pos++;
print_timeval(cases);
}
理由は、
- 関数ポインタ経由
- インライン展開を防ぐためです、インライン展開された関数は他の関数に比べてcall, retの負荷が減る分、速く見えてしまいます
- -fno-builtin
- コンパイラの最適化レベルを上げると、単純なmemset関数の実装をコンパイラが検知してlibcのmemset呼び出しに置き換えてしまうことがあります。同じ関数を比較してもベンチマークの意味がないため、置き換えが発生しないように防いでいます。
測定結果
まずは良く使われる最適化レベルO2で測ってみます。
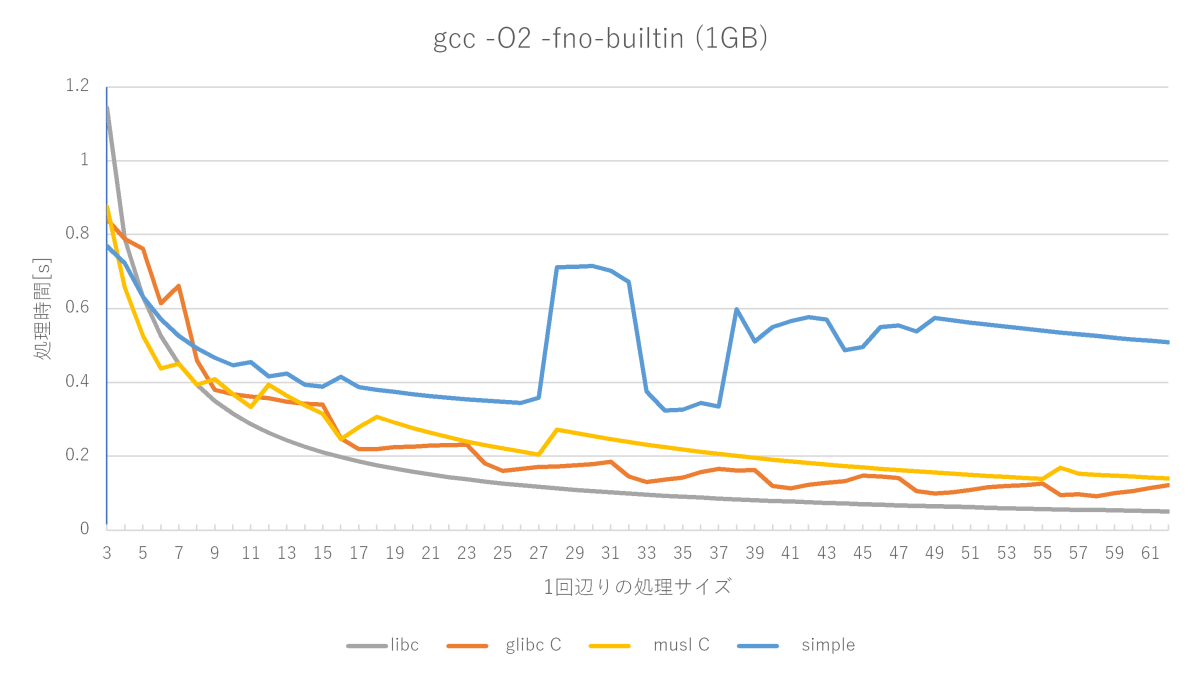
アセンブラで書かれたmemsetと比較すると、glibcやmuslの実装は遅いですが、かなり健闘していますね。一方で、単純なmemset実装はかなり性能が悪いです。
次はO3にしましょう。ほぼ最強の最適化レベルです。
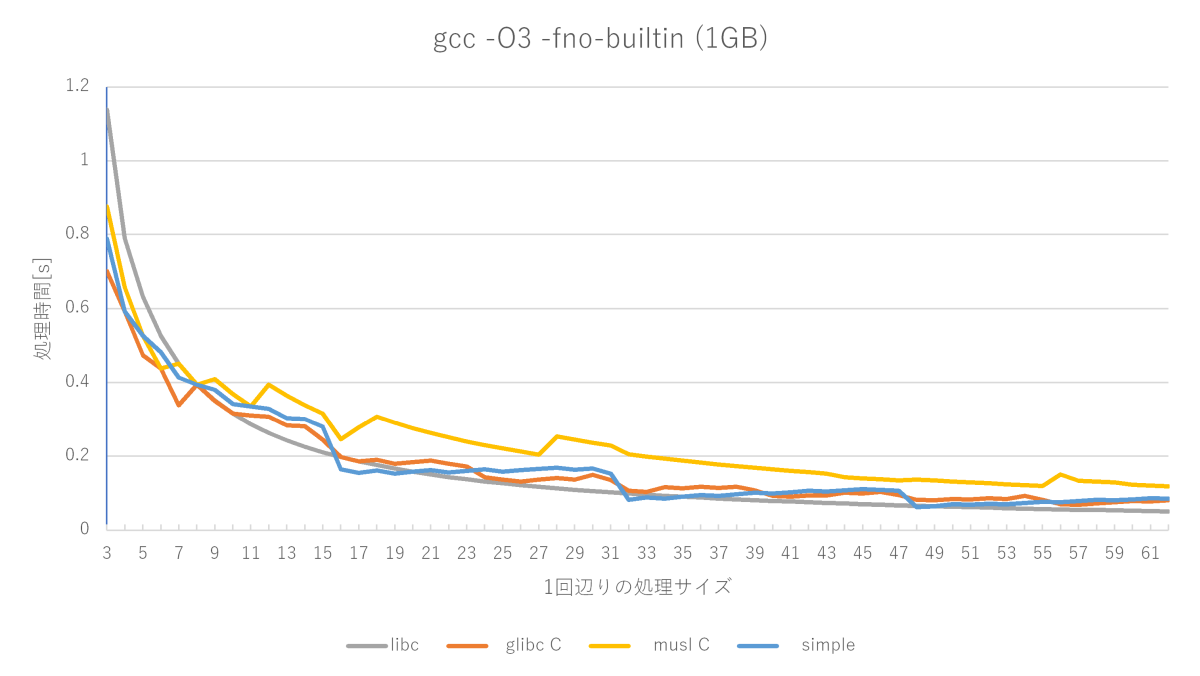
なんと単純なmemsetがメチャクチャ速くなり、muslの実装を超えてしまいました。最適化の威力恐るべし。
O2とO3は異なる最適化が働きますが、一番効いている要素はどれでしょう?O2にベクトル最適化オプションだけ追加してみます。
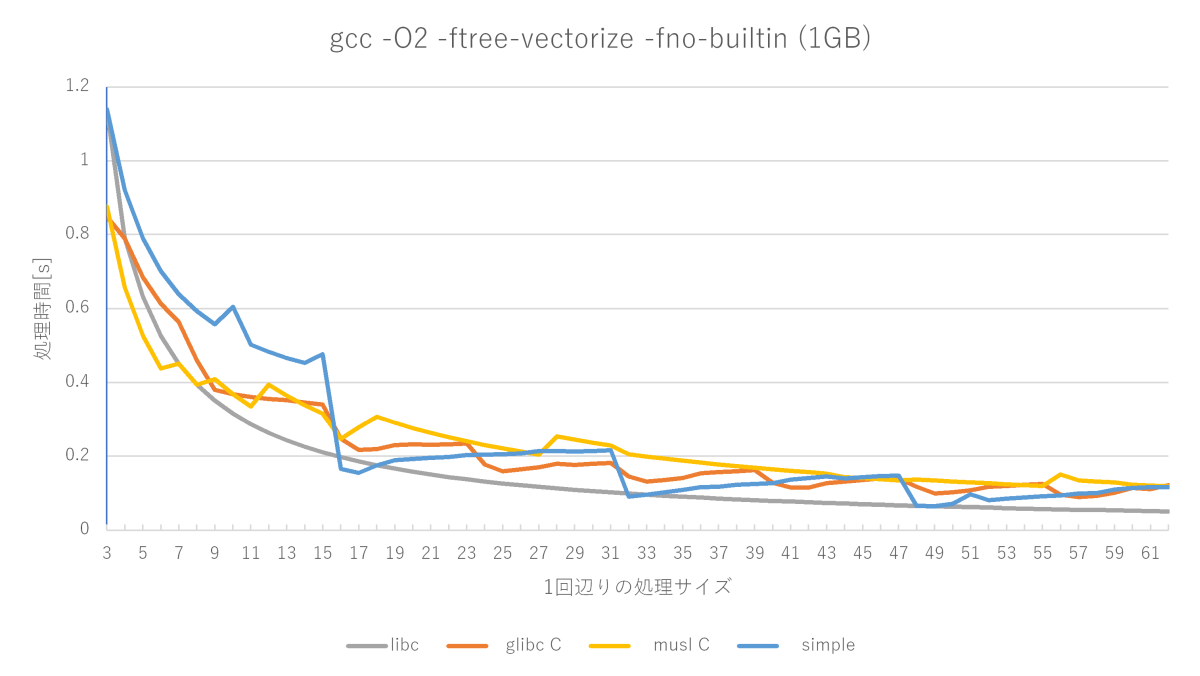
gcc -O2 -ftree-vectorize -fno-builtinの測定結果
O3の性能グラフにかなり近づきました。ベクトル最適化が大きな性能改善要素となるようです。
Cライブラリの本気を見よ
ちなみにglibcやmuslはC言語による実装の他に、各アーキテクチャのためにアセンブラによる専用の実装を持っています。x86_64向けであればglibcもmuslも専用の実装を持っています。
このベンチマークの趣旨からは外れますが、アセンブラの実装も測ってみました。こんな感じです。
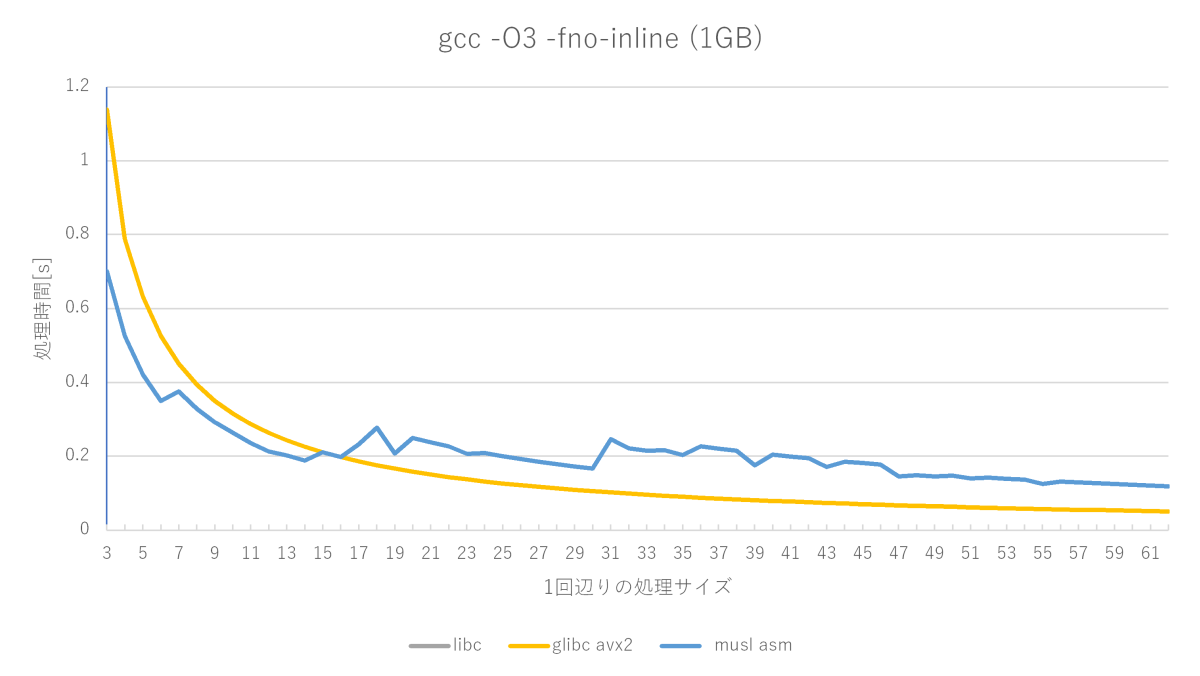
SSE2の実装(標準のmemsetはSSE2を使う)とAVX2の実装はほとんど速度差がありません。muslの実装はC言語版と比べると速い部分もありますが、glibcのマニアックな実装と比べると今一つですね……。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2019年12月13日
muslのmemset関数
目次: ベンチマーク
musl C library(サイトへのリンク)のmemset関数の実装はかなり気合が入っており、特に先頭&終端データの処理が面白いです。
こんなコードです。
musl memset関数のバッファ先頭&終端処理
if (!n) return dest;
s[0] = c;
s[n-1] = c;
if (n <= 2) return dest;
s[1] = c;
s[2] = c;
s[n-2] = c;
s[n-3] = c;
if (n <= 6) return dest;
s[3] = c;
s[n-4] = c;
if (n <= 8) return dest;
私はぱっと見では何をしてるのかさっぱりわかりませんでした。図を書いてみてやっと意味が分かりました。
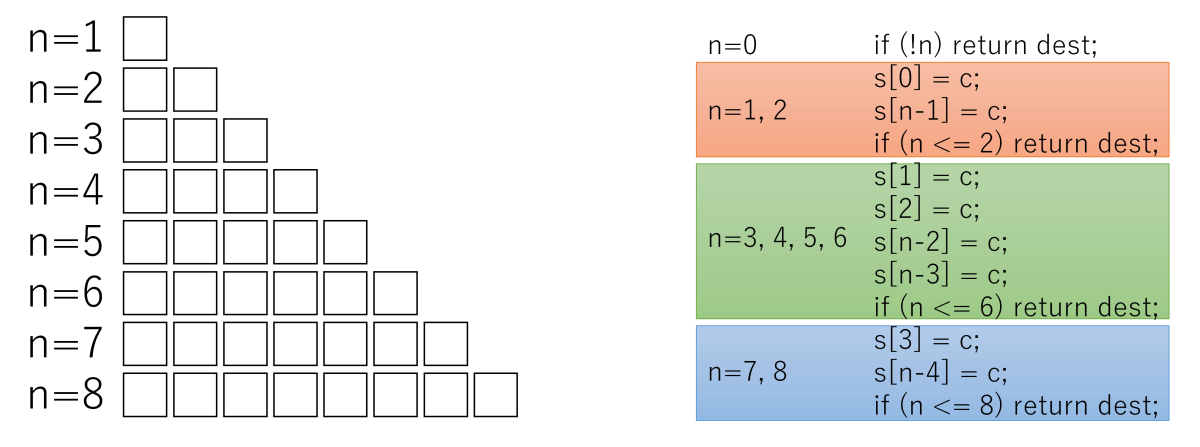
領域のサイズnが1〜8の場合、このコードだけで処理が終わります。説明の都合上、ifを区切りとして、3つのかたまり(赤、緑、青)に分けました。n = 1, 2の場合は赤だけ、n = 3, 4, 5, 6の場合は赤+緑、n = 7, 8の場合は赤+緑+青が実行されます。
ゴチャゴチャ説明するより、1ステップずつ、実行した結果を図示した方がわかりやすいかと思います。
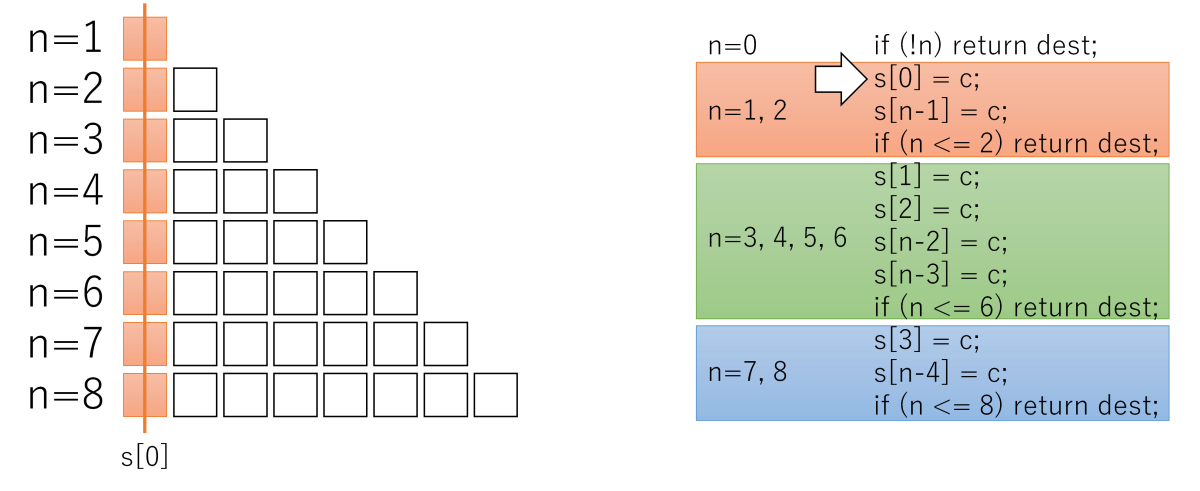
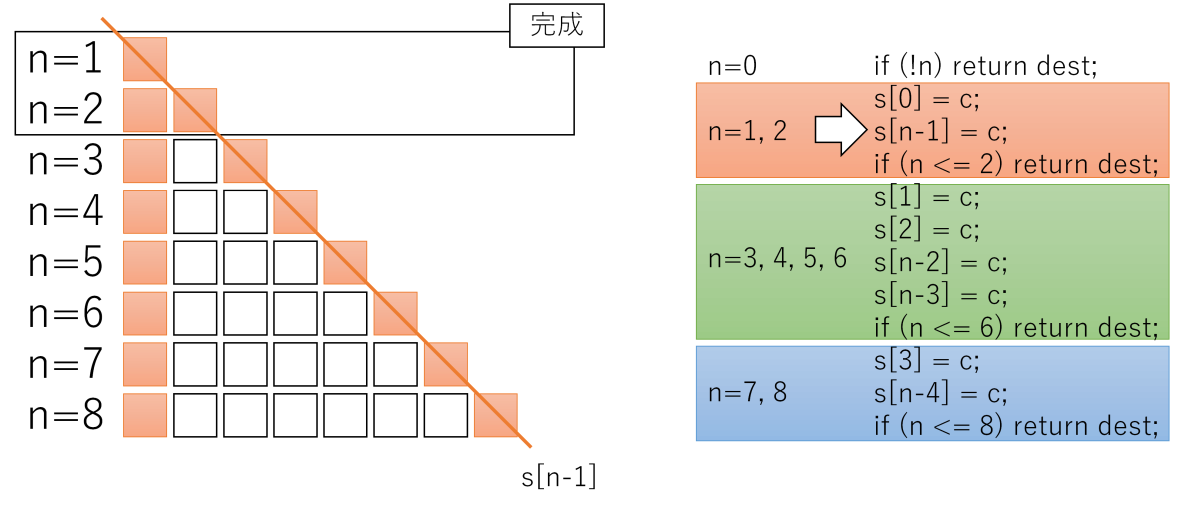
s[n - 1] = cまで、
n = 1, 2はmemset完了
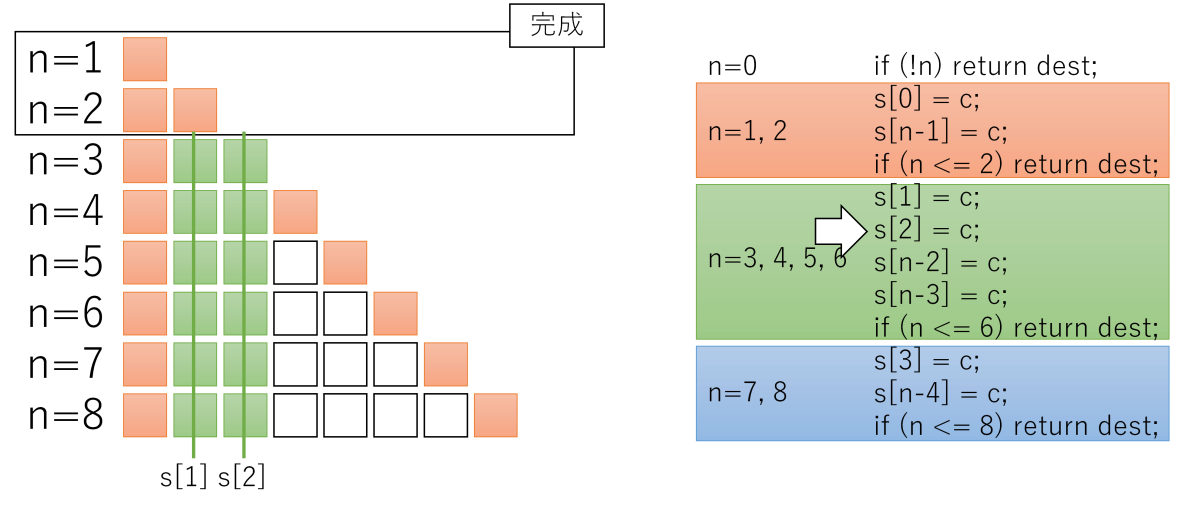
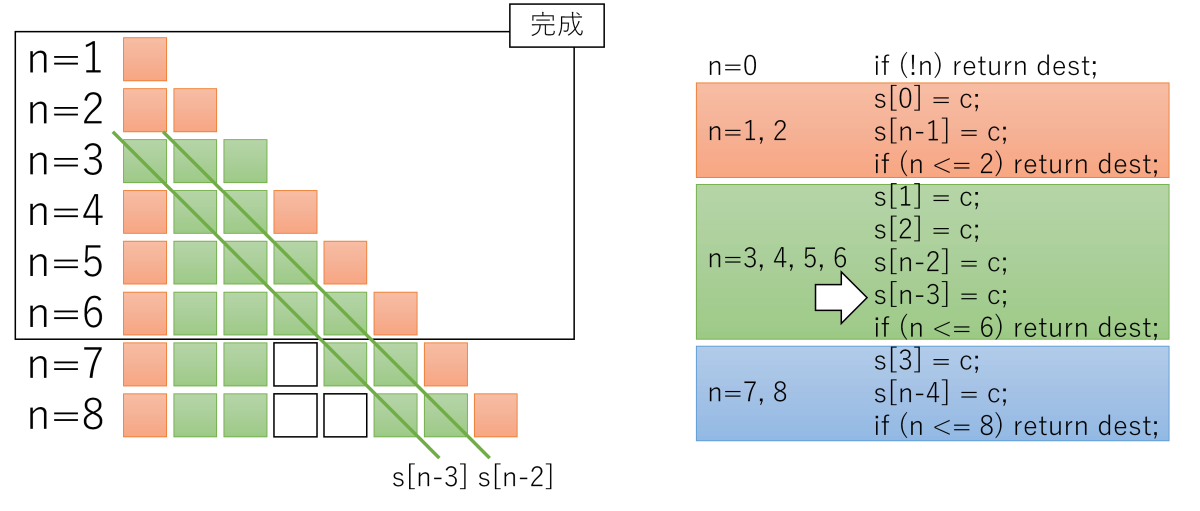
s[n - 2] = c, s[n - 3] = cまで、
n = 3, 4, 5, 6はmemset完了
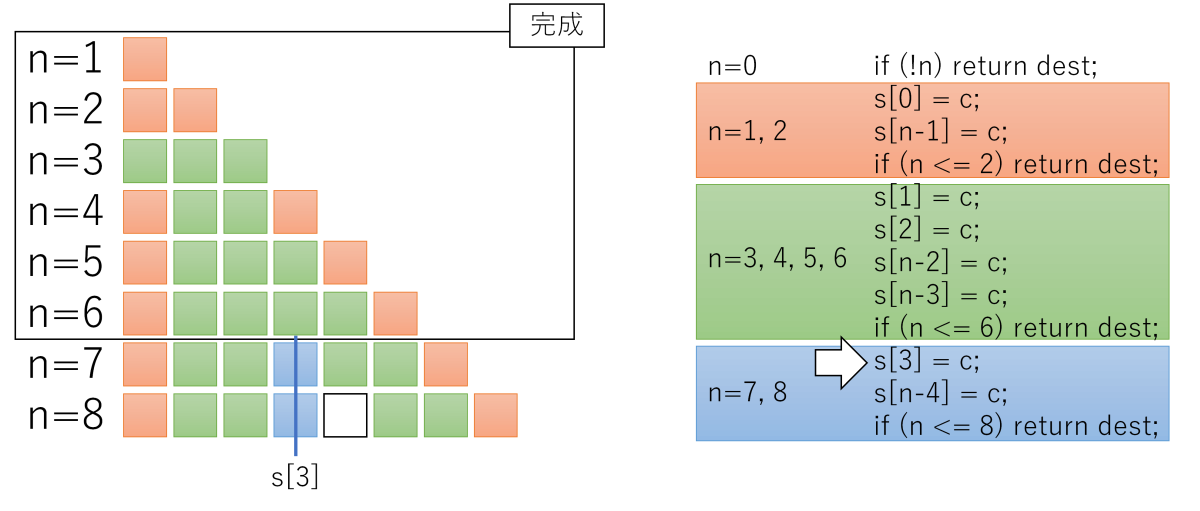
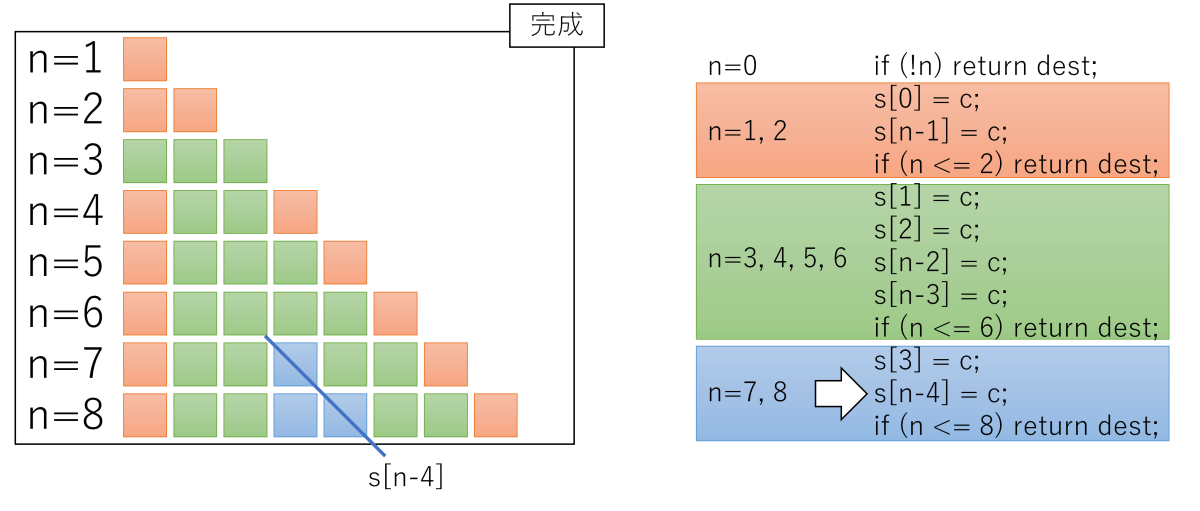
s[n - 4] = cまで、
n = 7, 8はmemset完了、それ以上のサイズは処理を継続
図を見るとわかるように、同じ領域に2回以上書く場合がありますが、memsetは同じ領域に2度書いても問題ありません(書き込む値は同じなので、何度書いても結果は同じ)。
この「何度書いても良い」性質を利用して、分岐を限界まで減らす戦略のようです。
ストアより分岐を減らす方がメリットがある、とみているわけですね。イマドキのCPUに合った最適化なのでしょうね。
メモ: 技術系の話はFacebookから転記しておくことにした。大幅に追記。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2019 | > | ||||
| << | < | 12 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | - | - | - | - |
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
