 未来から過去へ表示(*)
未来から過去へ表示(*) 2023年7月13日
PHP 8への道のり
目次: 自宅サーバー
この日記システムをPHPの最新バージョンPHP 8に対応させました。
きっかけはさくらインターネットから「PHP 5を使うのは危険だよ」というメールが来たことです。PHP 5.6のEOLは2018年なので5年くらい放置していたんですね。さすがにサボりすぎました。
PHP 5とPHP 7は互換性が保たれていて(PHP 6は欠番らしい)おり1文字も変更することなくPHPのバージョンアップに対応できました。ところがPHP 8は古い機能を色々と廃止したようで全く動きませんでした。
PHP 8で動かなくなった機能達
PHP 8で動かなくなった機能達のエラーメッセージや直し方(正しいかどうか知らない)を順不同で紹介したいと思います。
get_magic_quotes_gpc() 関数は廃止
PHP Fatal error: Uncaught Error: Call to undefined function get_magic_quotes_gpc()
この関数は説明を見ても常にfalseを返すと書いてあり、もはや存在しようがしなかろうが呼ぶ意味がありません。この関数を呼んでいるコードごと消しました。
クラスのコンストラクタが曲者でした。PHP 7までクラスと同名の関数がコンストラクタ扱いされましたが、PHP 8から __construct() がコンストラクタ扱いされます。この変更の影響であらゆるクラスの初期化が実行されなくなって、訳のわからないエラーを引き起こしました。デバッグが一番面倒くさかったです。
波括弧のオフセット指定は廃止
PHP Fatal error: Array and string offset access syntax with curly braces is no longer supported
PHP 8では波括弧 {} によるオフセットの指定が廃止されたので、角括弧 [] に置き換える必要があります。難しくはないですが、地味に使っている箇所が多く修正が大変でした……。
each() 関数は廃止
PHP Fatal error: Uncaught Error: Call to undefined function each()
PHP 8ではeach() 関数が廃止されました。これも複数ヶ所で使っていて修正が面倒でした。
修正例
// 修正前
reset($array);
list($a, $b) = each($array);
// 修正後
reset($array);
$a = key($array);
$b = current($array);
上記のように先頭のキーと値を取り出すためだけに使っていたので、単純にkey() とcurrent() 関数で書き換えました。
mb_strrpos() の引数
PHP Fatal error: Uncaught TypeError: mb_strrpos(): Argument #3 ($offset) must be of type int, string given
PHP 7はmb_strrpos() 関数の3番目の引数(offsetの位置)にencodeを指定してもエラーにならなかったのですが、PHP 8ではoffset, encodeを指定しないとエラーになるようです。PHPは良くわかりませんなあ。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2023年7月12日
自宅のサーバーとPHP
目次: 自宅サーバー
自宅のファイルサーバー兼WebサーバーでPHPが動かなくなっていました。
素のPHP 8すら動かないので、おそらくPHP 5の寿命が尽きたときにPHP周りの設定が全部吹っ飛んで動かなくなったと思われます。自宅のWebサーバーは自宅から見えないので、長らく気づいていませんでした……。あれまあ。
まずはPHP CGIや日記システムで使っているGDやmbstringをインストールします。
PHPのインストール
# apt-get install php-cgi php-gd libapache2-mod-php8.2 php8.2-mbstring
Apache 2の設定ファイルを変更してPHP 8.2を有効にします。
Apache 2でPHP 8.2を有効にする
# cd /etc/apache2/mods-enabled # ln -s ../mods-available/php8.2.conf # ln -s ../mods-available/php8.2.load # systemctl restart apache2
Apache 2はユーザーディレクトリといって /home/username/public_html/ ディレクトリに置いたファイルが、URL /~username/ で見える仕組みがありまして、日記システムはユーザーディレクトリに配置しています。
初期状態のphp8.2.confだとユーザーディレクトリの配下にあるPHPスクリプトは動きません。わざと無効化してあります。
php 8.2のユーザーディレクトリの設定
# /etc/apache2/mods-enabled/php8.2.conf
#...略...
# Running PHP scripts in user directories is disabled by default
#
# To re-enable PHP in user directories comment the following lines
# (from <IfModule ...> to </IfModule>.) Do NOT set it to On as it
# prevents .htaccess files from disabling it.
<IfModule mod_userdir.c>
<Directory /home/*/public_html>
php_admin_flag engine Off
</Directory>
</IfModule>
コメントにある通りIfModuleタグごと全てコメントにして、Apache 2を再起動しましょう。これできっとPHP 8が動くはずです。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年7月8日
日本語文字コードのメモ
目次: PC
昔、文字コードを調べたときのメモです。文字コードは詳しいサイトがたくさんあって、私が書けることはほとんどないんですが……詳しいサイトが一部消えてしまったようなので、メモを残しておきます。
JIS区点番号
JIS X 0208:1997を見ると、漢字集合を94個の区、94個の点(区点番号)で定義しています。全部で94x94 = 8336字あります。区点番号をどのバイト値として表現するか?を符号化方式とか符号化表現と言いまして、普及している方式がいくつかあります。
ISO/IEC 2022に出てくる用語G0やGL/GRやエスケープシーケンスを説明なしに使います。私もマスターという訳ではなく、調べて説明するのもしんどいので、他の詳しいサイト様を参照くださいませ。
RFC 1468(いわゆるISO-2022-JP, JISコード)
RFC 1468(リンク)で定義された符号化方式です。JISだとJIS X 0208付属書2に規定があります。MIMEではISO-2022-JPという名前で、JISコードと呼ぶ人もいますが、ISO規格でもJIS規格でもなく、RFCです。変な名前ですね……。
7bitで符号化し、第1、第2バイトともに、0x21〜0x7E(94個)の範囲を使用します。全部で94x94 = 8836字となります。区点番号と同じで素直ですね。文字集合は4つあり、エスケープシーケンスで切り替えます。
RFC 1468 (ISO-2022-JP) の使用する文字集合とエスケープシーケンス
Esc Seq Character Set ISOREG
ESC ( B ASCII 6
ESC ( J JIS X 0201-1976 ("Roman" set) 14
ESC $ @ JIS X 0208-1978 42
ESC $ B JIS X 0208-1983 87
ISO/IEC 2022的に見ると、G0がASCII、GLにG0がロッキングシフトされている初期状態です。7bitコードなのでGRは使いません。呼び出しInvokeは使いませんのでGLはずっとG0のままです。エスケープシーケンスESC ( はG0への94文字集合(ASCIIなど)の指示Designateで、ESC $ はG0への94n文字集合(漢字など)の指示です。
- GL領域: G0固定
- GR領域: なし
- G0: ASCII, JIS X 0201ローマ字, JIS X 0208
- G1: 使わない
- G2: 使わない
- G3: 使わない
7bit文字しか理解できないサーバーなどを経由して文章を交換しても、情報が欠落しないように工夫された方式です。その代償と言うのかJIS X 0201片仮名、いわゆる「半角カナ」が使えません。表現する方法がないからです。
EUC-JP(Extended Unix Code)
EUC-JPが最初に規格化された場所は調べても良くわかりませんでした……。JISだとJIS X 0213付属書3に参考として表記されている符号化方式です。EUC-JIS-2004と呼ばれます。
8bitで符号化し、第1、第2バイトともに0xA1〜0xFE(94個)の範囲を使用します。全部で94x94 = 8836字となり、これも区点番号と同じで素直ですね。半角カナも対応しています。え、要らない?そう?
ISO/IEC 2022的に見ると、文字集合は4つあり、シングルシフトを使ってシフトの直後1文字分だけ切り替えます。エスケープシーケンスは使いません。
- GL領域: G0固定
- GR領域: G1, G2 (シングルシフト2、SS2で切り替え), G3 (シングルシフト3、SS3で切り替え)
- G0: ASCII
- G1: JIS X 0208
- G2: JIS X 0201片仮名
- G3: JIS X 0212補助漢字
ASCIIと漢字以外の文字、例えば半角片仮名を連発すると「シングルシフト+文字」のペアが連発されることになって容量的に効率が悪いですが、EUC-JPには大きな利点があります。
- エスケープシーケンスによる漢字集合の指示を使わないので、G0〜G3に指示された漢字集合を覚える必要がない
- ロッキングシフトによる呼び出しを使わないので、GLやGR領域に呼び出されたバッファを覚える必要がない
もっと平たく言いましょう。ISO-2022-JPは同じバイト列でも文字の種類(ASCIIか漢字か)がわかりません。最後に出てきたエスケープシーケンス次第で変わるためです。EUC-JPは文字列の途中から読みだしても文字の種類が判定できますので、文字列処理を行う際にはありがたい方式と言えるでしょう。
Shift JIS
元々はMicrosoftによる符号化方式です。JISだとJIS X 0208:1997付属書1に規定されています。「シフト符号化表現」が正式名称ですが、大抵Shift JISと呼びます。昔はJIS規格ではありませんでしたが、途中でJIS規格に取り込まれたのだとか。
第1バイトに0x81〜0x9F(31個)、0xE0〜0xEF(16個)が現れたら、第2バイト0x40〜0x7E(63個)、0x80〜0xFC(125個)が続きます。全部で47x188 = 8836字で、総数は同じですがちょっと変則的です。
ISO/IEC 2022的にはそもそも規格に沿っていないため特に何もないですね……。文字集合の切り替えやエスケープシーケンスのような仕組みは一切ありません。
Shift JISはEUC-JPと似たような特徴を持っていて、文字列の途中から読みだしても文字の種類が判定できます。また第1バイトの範囲は、英数字 (ASCII、0x21〜0x7E)や1バイト仮名(半角カナ、0xA1〜0xDF)と重複しないように配置され、シングルシフトのような仕組みなしに漢字と半角片仮名が使えます。
ISO/IEC 2022のような複雑な仕組みを理解する必要がない反面、拡張性が低いという大きな欠点があります。Shift JIS制定後にJIS X 0213が増えたとき、第1バイトの未使用領域0xF0〜0xFCで凌いだ(Shift JIS 2004)ものの、残された領域はもうありません。
コメント一覧
- hdkさん(2023/07/10 08:35)
ISO-2022-JPでもJIS X 0201片仮名はESC ( Iで表せばいいと思うんですけど、単にそれは使わないきまりにしたっぽいですよね。昔は電子メールでよくISO-2022-JPが使われていましたが、ESC ( IだったりSS2だったり、各クライアントが好き勝手な方法で表現していたような... 未だにiso-2022-jpといいながらESC ( Iでカタカナ入れて送ってくるコストコなんて店もありますが... (^^; - すずきさん(2023/07/10 11:22)
ISO-2022-JP の独自改変は詳しくなかったんで、そんなクライアントあるんだ……とためになりました。RFC 1468 の G2 は未定義で SS2 は明らかに間違ってる気がしますね。EUC-JP と勘違いか、間違っているのを知っていて借りてきたんですかねえ?
JIS X 0208 に片仮名(いわゆる全角カナ)はあるので、要らんと言えば要らんのですが、まあそんな単純な話じゃなかったってのは面白いところだなあと思います。
この記事にコメントする
2023年7月2日
Twitterの閲覧数制限
TwitterがWeb APIの利用を有料化&メチャクチャ高額な料金設定にしたため、ツイート情報をスクレイピングで取得しようとする人が増加して、Twitterのトラフィックが増えているようです。Twitterはスクレイピングに対する一時的な制限として、
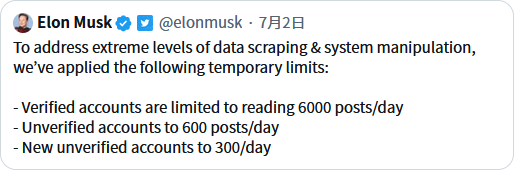
Twitterの制限に関するElon Maskさんのツイート
このような制限を掛けました。文字起こししておくと
To address extreme levels of data scraping & system manipulation, we've applied the following temporary limits:
- Verified accounts are limited to reading 6000 posts/day
- Unverified accounts to 600 posts/day
- New unverified accounts to 300/day
です。つまり、
- 青バッジあり: 6000件/日
- 青バッジなし: 600件/日
この制限は結構厳しくて、普通の使い方でも割とすぐに上限に達します。特に青バッジなしの600件/日は厳しそうです……。しかも笑えることにこの制限、他ならぬツイ廃のElon Maskさん自身にも適用されてしまいました。彼はTwitterの会長兼CTOなので権力をフル活用(?)して、制限を速攻で緩和させ数時間後には、
- 青バッジあり: 6000→8000→10000件/日
- 青バッジなし: 600→800→1000件/日
となっていました。行き当たりばったりですね〜。これもTwitterっぽいなーと思いますけど。
私の場合Twitterと自分の生活はあまり関係ないので、今回みたいに制限や緩和でお祭り騒ぎになろうと「ハハハ、何してんだTwitterウケるわ」程度で済みますが、Twitterが商売の生命線(商品の宣伝に使うとか)な人は「何してくれてんだ、ナメてんの??」と怒りたくもなるでしょうね。
制限が少し違う形で発動した
私は青バッジユーザーなせいかしばらく制限には引っかからなかったのですが、半日くらい使っていたらついにエラーが出ました。

エラーメッセージを文字起こししておくと、
このリクエストは、コンピュータによる自動的なものと判断されました。アカウントをスパムやその他の迷惑行為から保護するために、現在この操作は実行できません。しばらくしてからやりなおしてください。
いいね!とツイートはできないのになぜかリツイートだけはできるのも謎です。制限の掛け方を間違ってるのでは?という気がしてなりません。
Twitterの悪い癖
制限を掛けるなとは思いませんが、何も言わずに突然仕様を変えるのはTwitterの良くない癖だと思います。1日前でも良いから予告してからやればあまり混乱しないのに……。今回も突然制限を掛けたので「バグか?サーバーの不具合か!?」と騒ぎになっていました。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年6月30日
OpenOCDで独自のCSRを読みだす
目次: OpenOCD
忘れてしまうので。RISC-Vの独自(もしくは標準に準拠しているものの新しすぎるなど)のCSR(Control and Status Register)を読み出す方法をメモしておきます。GDBでOpenOCDに接続しinfo reg (レジスタ名) とすると内容が読み出せます。
CSRの名前指定で読み出す方法
(gdb) info reg mscratch mepc mcause mtval mip mscratch 0x0 0 mepc 0x6000c580 1610663296 mcause 0xb 11 mtval 0x0 0 mip 0x880 2176
もう一つの方法としてCSRの番号指定でも読み出せます。csr(番号) という名前になります。番号は10進数で指定するようで、例えばmscratch (0x340) なら832になります。
CSRの番号指定で読み出す方法
(gdb) info reg csr832 csr833 csr834 csr835 csr836 csr832 0x0 0 csr833 0x6000c580 1610663296 csr834 0xb 11 csr835 0x0 0 csr836 0x880 2176
これだけだと名前がわかりにくいだけで特に嬉しくありませんが、これから紹介するOpenOCDの設定と組み合わせると任意のCSRが読み出せるようになって非常に便利です。
NS31を例に
例としてNSITEXE NS31のRNMI CSR(mnscratch, mnepc, mncause, mnstatus(※))を読み出してみましょう。
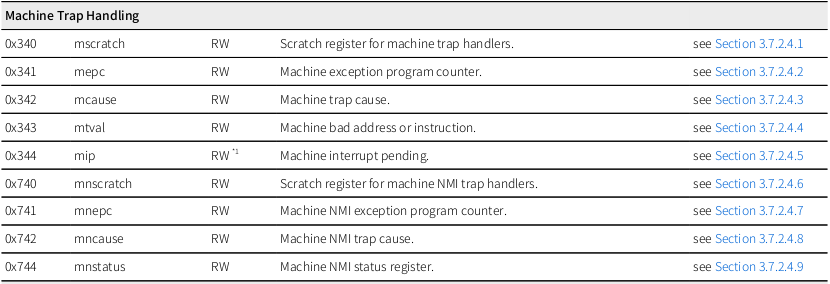
書き起こしておくと0x740 mnscratch, 0x741 mnepc, 0x742 mncause, 0x744 mnstatus です。10進数ですと1856, 1857, 1858, 1860ですね。これらのCSRを読みだそうとしても、OpenOCD側が存在を認識していないためエラーになります。
未対応のCSRの読み出し
(gdb) info reg csr1856 Invalid register `csr1856'
CSRを読むためにOpenOCDを書き換えて再ビルドして……では大変すぎます。そんなお困りごとをOpenOCDもわかっていて救済策が用意されています。
OpenOCDの設定
riscv expose_csrs 1856-1860
この一行を追加してもう一度試すと、
expose_csrsで追加したCSRの読み出し
(gdb) info reg csr1856 csr1857 csr1858 csr1860 csr1856 0x0 0 csr1857 0x180188e 25172110 csr1858 0x80000000 -2147483648 csr1860 0x8 8
無事読み出すことができました。
(※)このレジスタは独自CSRではなくResumable NMIという規格で提案中のレジスタです。が、OpenOCDが未対応という意味では独自レジスタと同じなので、この例で取り上げました。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2023 | > | ||||
| << | < | 07 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | - | - | - | 1 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 | - | - | - | - | - |
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
