 未来から過去へ表示(*)
未来から過去へ表示(*) 2023年12月10日
fno-builtinによるlibc関数呼び出し最適化の抑制
目次: GCC
GCCはlibcの関数呼び出しを別の関数呼び出しに置き換える最適化(名前がわからないので以降「libc関数呼び出し最適化」と呼びます)を行います。例を挙げると、
- 1文字出力するprintf関数→putchar関数
- 行末に改行がある文字列を出力するprintf関数→puts関数
時には勝手にlibcの関数呼び出しを置き換えてほしくないこともあると思います。libc関数呼び出し最適化を抑えることができるコンパイラオプションfno-builtinを指定したときの挙動についてメモしておきます。
GCCのバージョンは下記のとおりです。
GCCのバージョン
$ gcc --version gcc (Debian 12.2.0-14) 12.2.0 Copyright (C) 2022 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
テストに使うプログラムは下記の通りです。
テストプログラム
int printf(const char *a, ...);
void _start(void)
{
printf("\n");
}
特に何も指定しなければ、1文字出力するprintfはputchar呼び出しに置き換えられるはずです。確認のためnostdlibオプションを付けてコンパイルし、リンクエラーを見るとprintfの呼び出しがどの関数に置き換えられたかわかります。
nostdlibでのコンパイル、リンク結果
$ gcc -O2 -g -Wall a.c -nostdlib /usr/bin/ld: /tmp/cc1D673J.o: in function `_start': /home/katsuhiro/share/test_gcc_no_builtin/a.c:5: undefined reference to `putchar' collect2: error: ld returned 1 exit status
リンクエラーは「putcharがない」と出ました。printfの呼び出しがputcharの呼び出しに置き換えられたことがわかりますね。次はfno-builtinオプションを指定します。
fno-builtin、nostdlibでのコンパイル、リンク結果
$ gcc -O2 -g -Wall a.c -nostdlib -fno-builtin /usr/bin/ld: /tmp/cc6JbRD2.o: in function `_start': /home/katsuhiro/share/test_gcc_no_builtin/a.c:5: undefined reference to `printf' collect2: error: ld returned 1 exit status
リンクエラーは「printfがない」と出ました。fno-builtinオプションによってprintfからputcharへの置き換えが抑制されたことがわかります。
fno-builtinの仕様なのか?
動作結果を見る限りfno-builtinオプションでlibc関数呼び出し最適化が抑制されましたが、この挙動がオプションの仕様か?と聞かれると正直良くわかりません。
仕様はGCCのマニュアル(Other Builtins (Using the GNU Compiler Collection (GCC)))に書かれていて、説明によれば残りのビルトイン関数(printfを含む)は最適化のために提供されている("The remaining functions are provided for optimization purposes.")とあります。
- ビルトイン関数を無効にした
- 最適化後に呼び出すためのビルトイン関数がない
- libc関数呼び出し最適化そのものが無効になった
私はこのような動作をしているものと推測しています。正しいかどうかは知りません……。
最適化はビルトイン関数に頼る必要はありません。つまりfno-builtinオプションで抑制できないようなlibc関数呼び出し最適化があっても不思議ではありません。今のところそのような例は見つけていませんが、もしあったとすると抑制する方法はあるのでしょうか?うーん??
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2023年12月3日
musl libcのpthread_barrier_wait()の実装 その3、インスタンス
目次: C言語とlibc
参考: 図を書くために使った PlantUMLのコードです。
PlantUMLのコードです。
前回の続きです。musl libc 1.2.4のpthread_barrier_wait()の実装と動作の概要です。バリアに到達したスレッドがNスレッド(N >= 2)あるとすると、大きく分けて3つの役割に分かれます。役割名は私が適当に付けました。正式な名前はあるのかな?
- Owner: 最初にバリアに突入してきたスレッド(1スレッド)
- Last: 最後にバリアに突入してきたスレッド(1スレッド)
- Others: OwnerでもLastでもないスレッド全て(0〜N-2スレッド、平たく言えば3スレッド以上のバリアのときだけ存在する)
今回はインスタンスがなぜローカル変数として確保されるかを紹介します。1回目と2回目のバリアが重なるところがポイントです。
スレッドの役割は変わる
各スレッドはOwnerかLastかOthersになりますが、役割は毎回のバリア同期処理ごとに変わります。例えばバリアとバリアの間の処理時間が同じだとすると、あるバリアのOwnerは次のバリアではLastになる可能性が高いです。Ownerはバリアから最後に脱出しますので、その間に他のスレッドの処理が進んで次のバリア同期処理のOwnerになるからです。
3スレッドあって下記のように役割が変化する場合を考えてみます。
- スレッド1: Owner1, Last2: 1回目Owner、2回目Last
- スレッド2: Others1, Owner2: 1回目Others、2回目Owner
- スレッド3: Last1, Others2: 1回目Last、2回目Others
更に考えてみるとバリアとバリアの間の処理時間が非常に短い場合、1回目のバリアのOwner(スレッド1、Owner1, Last2)がバリアを脱出する前に、違うスレッドが2回目のバリアのOwner(スレッド2、Others1, Owner2)となってバリアに到達している可能性があります。シーケンス例は下記のようになります。
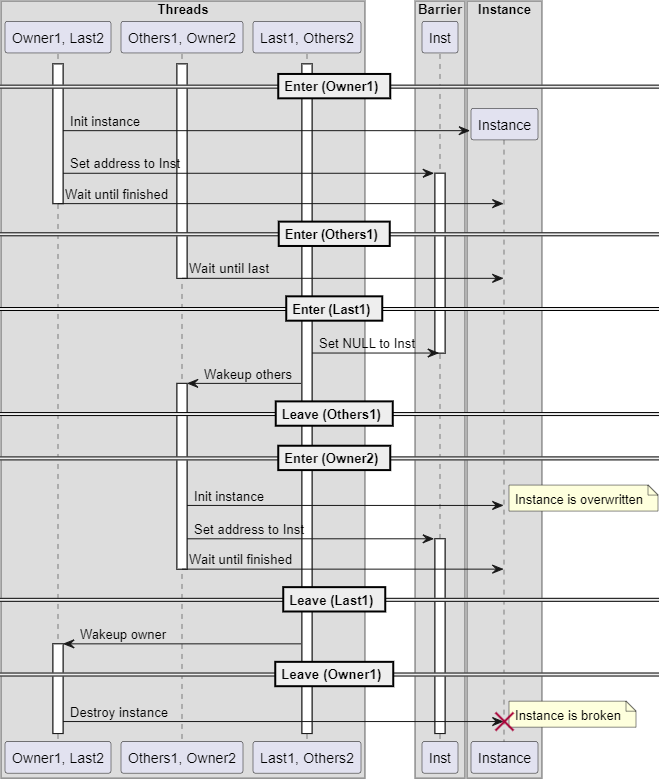
もしバリアのインスタンスをグローバル変数などに確保した場合、1回目のバリアのOwner(スレッド1、Owner1, Last2)によるインスタンスの破棄と、2回目のバリアのOwner(スレッド2、Others1, Owner2)のインスタンスの初期化がぶつかって、お互いに内容を壊しあうため正常に動作しません。
この問題を解決にはインスタンスをOwnerスレッド固有の領域に置くと良いです。1回目のバリアのOwnerスレッドと、2回目のバリアのOwnerスレッドがそれぞれ別の領域に置けば、お互いに壊し合うことがなくなります。
ローカル変数はスレッド固有の領域
スレッドごとの固有の領域として使えるのは、
TLS(Thread Local Storage) ヒープから確保したメモリ(mallocなど) ローカル変数があります。インスタンスを各Ownerスレッド固有の領域においたとき、2回分のバリア動機処理のシーケンス例は下記のようになります。
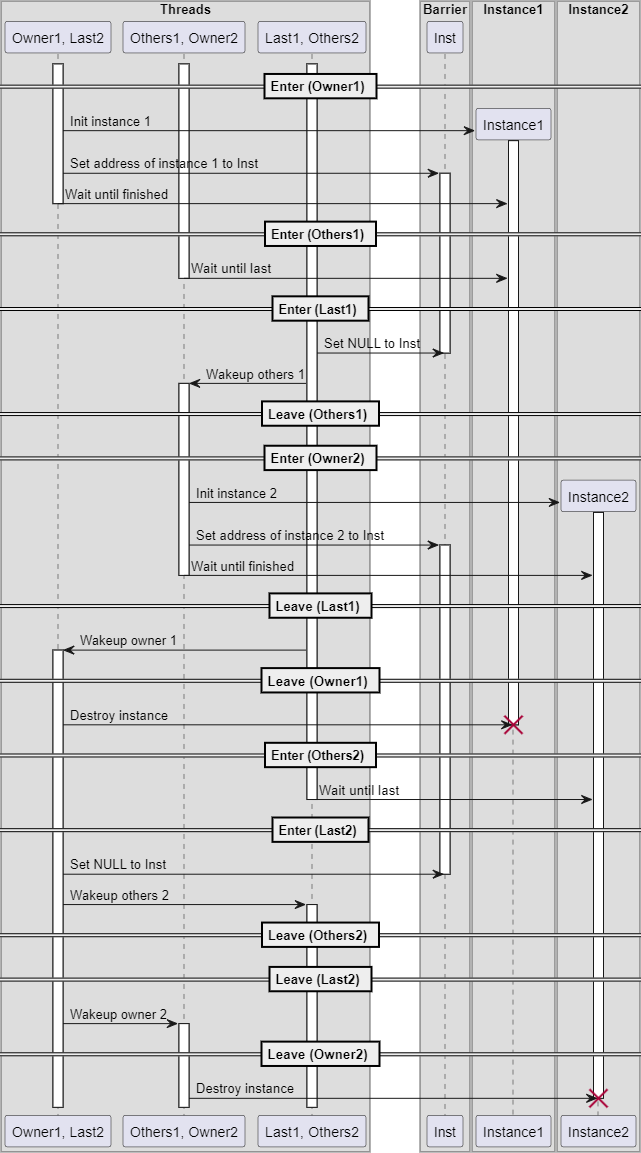
バリアのインスタンスは複数スレッド間で共有する領域です。ローカル変数を複数スレッド間で共有すると、ローカル変数が破棄されたときに問題が発生するので、ヒープを使うことが多いでしょう。
しかし前回説明したようにバリア同期処理の場合はローカル変数の寿命をうまく制御できるため、複数スレッド間で共有しても問題が起きません。インスタンスをローカル変数に確保すると、ヒープに比較して高速なメモリ割当が可能です。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年12月2日
musl libcのpthread_barrier_wait()の実装 その2、LastとOthers
目次: C言語とlibc
前回の続きです。musl libc 1.2.4のpthread_barrier_wait()の実装と動作の概要です。バリアに到達したスレッドがNスレッド(N >= 2)あるとすると、大きく分けて3つの役割に分かれます。役割名は私が適当に付けました。正式な名前はあるのかな?
- Owner: 最初にバリアに突入してきたスレッド(1スレッド)
- Last: 最後にバリアに突入してきたスレッド(1スレッド)
- Others: OwnerでもLastでもないスレッド全て(0〜N-2スレッド、平たく言えば3スレッド以上のバリアのときだけ存在する)
いっぺんに説明すると意味不明なので、順番に説明します。今回はLastとOthersです。
LastとOthers(到達側)
自分がLastかどうか判定する条件はバリア変数の_b_instがNULL以外であり、インスタンスのカウントがバリア同期するスレッド数と一致(= 最後に到達した1スレッド)することです。Lastのやることはバリア変数(pthread_barrier_t)に設定されたインスタンスを消すことと、バリア同期を待っているOthersを起こすことです。
Lastがこの時点でb->_b_instをNULLにしていること、ローカル変数instを使っていてb->_b_instを使わないことには理由があって、次のバリア処理とのオーバーラップと関係しています。同時に説明するとややこしいので、次回ご説明しようと思います。
OwnerとLast以外は全部Othersスレッドとなります。OthersのやることはLastが来るまで待つことです。
LastとOthersの到達側に関連するコードは下記のとおりです。
pthread_barrier_wait()のLastとOthersの到達側のコード
// musl/src/thread/pthread_barrier_wait.c
int pthread_barrier_wait(pthread_barrier_t *b)
{
int limit = b->_b_limit;
struct instance *inst;
/* Trivial case: count was set at 1 */
if (!limit) return PTHREAD_BARRIER_SERIAL_THREAD;
/* Process-shared barriers require a separate, inefficient wait */
if (limit < 0) return pshared_barrier_wait(b);
/* Otherwise we need a lock on the barrier object */
while (a_swap(&b->_b_lock, 1))
__wait(&b->_b_lock, &b->_b_waiters, 1, 1);
inst = b->_b_inst;
/* First thread to enter the barrier becomes the "instance owner" */
if (!inst) {
//★★Ownerのスレッドの処理は省略(その1をご覧ください)★★
}
/* Last thread to enter the barrier wakes all non-instance-owners */
if (++inst->count == limit) {
//★★Lastのスレッドはこちら★★
b->_b_inst = 0;
a_store(&b->_b_lock, 0);
if (b->_b_waiters) __wake(&b->_b_lock, 1, 1);
a_store(&inst->last, 1);
if (inst->waiters)
__wake(&inst->last, -1, 1);
} else {
//★★Othersのスレッドはこちら★★
a_store(&b->_b_lock, 0);
if (b->_b_waiters) __wake(&b->_b_lock, 1, 1);
__wait(&inst->last, &inst->waiters, 0, 1);
}
細かい部分は省いてシーケンスの例を1つだけ示せば下記のようになります。
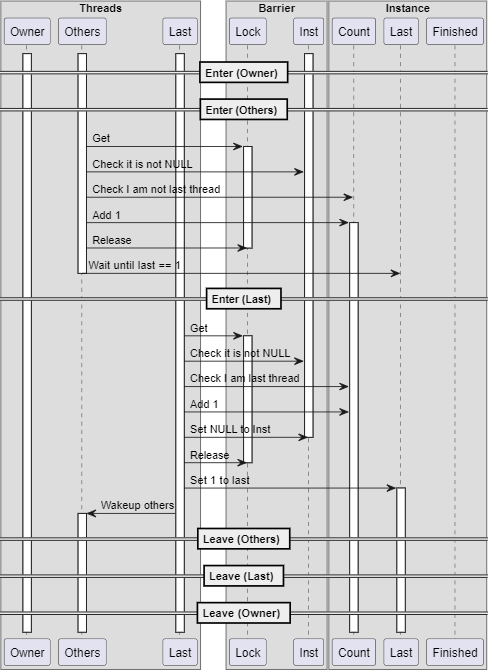
pthread_barrier_wait()のLastとOthersの到達側シーケンスの一例
見たままなので解説することがないですね。全員でインスタンスのカウントを+1して、最後のスレッドLastだけが特殊な処理を行います。
LastとOthers(脱出側)
脱出側のやることは単純ですが役割分担が少しややこしいです。到達側と同様にLastとOthersに役割が分かれますが、到達側のLast = 脱出側のLastとは限らないからです。
脱出時のLastになる条件はインスタンスのカウント値が1であることです。到達時にLastであったかOthersであったかは無関係です。脱出時のLastのやることは、インスタンスのfinishedを+1して待機中のOwnerスレッドを再開させることです。
脱出時のOthersになる条件はLastではない、インスタンスのカウント値が1以外であることです。
LastとOthersの脱出側に関連するコードは下記のとおりです。
pthread_barrier_wait()のLastとOthersの脱出側のコード
// musl/src/thread/pthread_barrier_wait.c
int pthread_barrier_wait(pthread_barrier_t *b)
{
int limit = b->_b_limit;
struct instance *inst;
//★★略★★
/* Last thread to exit the barrier wakes the instance owner */
if (a_fetch_add(&inst->count,-1)==1 && a_fetch_add(&inst->finished,1))
__wake(&inst->finished, 1, 1);
return 0;
}
細かい部分は省いてシーケンスの例を1つだけ示せば下記のようになります。
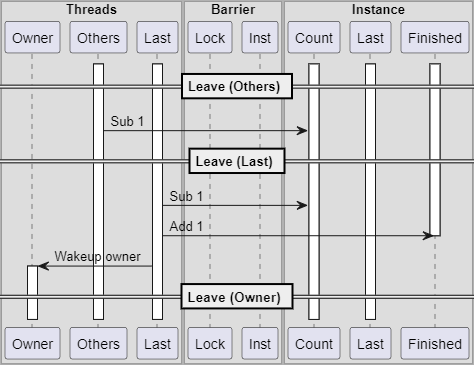
pthread_barrier_wait()のLastとOthersの脱出側シーケンスの一例
到達側のLastスレッドの処理では待機していたOthersスレッド達を全員再開させ、Lastも処理を再開します。するとLast + Othersスレッド全てがいっぺんに脱出側の処理を開始します。先ほど説明したとおり、どのスレッドが脱出側のLastになるかは運次第です。
実装の特徴はアトミックアクセスですかね。a_fetch_add(x, -1)はポインタxの指す先をアトミックに-1して、返り値でxの以前の値を返す関数です……といわれてもわかりにくいですよね。4スレッド(Owner, Others1, Others2, Last)の場合を書きましょうか。Ownerスレッドはカウント値を+1しないので、脱出処理開始時のカウント値は4 - 1 = 3です。
| スレッド | -1したあとのカウント値 | a_fetch_add()の返り値 |
|---|---|---|
| Others 1 | 2 | 3 |
| Others 2 | 1 | 2 |
| Last | 0 | 1 |
ちなみにアトミックアクセス以外の方法(if文とカウント値の変更など)では正常に動作しません。判定と値変更の間に他のスレッドが処理を行う可能性があるからです。
続きはまた今度。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年12月1日
musl libcのpthread_barrier_wait()の実装 その1、Owner
目次: C言語とlibc
誰得かわかりませんが、musl libc 1.2.4のpthread_barrier_wait()の実装と動作の概要です。このAPIはバリア同期を実現するためのAPIで、POSIXという規格の一部です。バリア同期はある地点に指定した数のスレッドが全員到達するまで、全スレッドを待機させる同期機構です。
バリアに到達したスレッドがNスレッド(N >= 2)あるとすると、大きく分けて3つの役割に分かれます。役割名は私が適当に付けました。正式な名前はあるのかな?
- Owner: 最初にバリアに突入してきたスレッド(1スレッド)
- Last: 最後にバリアに突入してきたスレッド(1スレッド)
- Others: OwnerでもLastでもないスレッド全て(0〜N-2スレッド、平たく言えば3スレッド以上のバリアのときだけ存在する)
いっぺんに説明すると意味不明なので、順番に説明します。最初はOwnerからです。
Owner
自分がOwnerかどうか判定する条件はバリア変数の_b_instがNULLであることです。Ownerのやることはインスタンスを作成しバリア変数(pthread_barrier_t)に設定することと、バリアから一番「最後」に脱出してインスタンスを破棄することです。インスタンスはmuslの用語ですかね?それはさておいてインスタンスは1回のバリア同期に必要なパラメータがおかれた場所です。
インスタンスの必要性を簡易に説明するのは難しいですね……バリア変数は使いまわされるからです。具体例で言うと、1回目のバリアからスレッドが脱出している途中で、先に脱出した他のスレッドが2回目のバリアに到達する、というケースが発生します。もしバリアのカウンタ値などをバリア変数に置いてしまうと、1回目のバリアの処理と2回目のバリアの処理が混ざって正常に処理できなくなります。
Ownerに関連するコードは下記のとおりです。
pthread_barrier_wait()のOwner関連のコード
// musl/src/thread/pthread_barrier_wait.c
int pthread_barrier_wait(pthread_barrier_t *b)
{
int limit = b->_b_limit;
struct instance *inst;
/* Trivial case: count was set at 1 */
if (!limit) return PTHREAD_BARRIER_SERIAL_THREAD;
/* Process-shared barriers require a separate, inefficient wait */
if (limit < 0) return pshared_barrier_wait(b);
/* Otherwise we need a lock on the barrier object */
while (a_swap(&b->_b_lock, 1))
__wait(&b->_b_lock, &b->_b_waiters, 1, 1);
inst = b->_b_inst;
/* First thread to enter the barrier becomes the "instance owner" */
if (!inst) {
struct instance new_inst = { 0 };
int spins = 200;
b->_b_inst = inst = &new_inst;
a_store(&b->_b_lock, 0);
if (b->_b_waiters) __wake(&b->_b_lock, 1, 1);
while (spins-- && !inst->finished)
a_spin();
a_inc(&inst->finished);
while (inst->finished == 1)
__syscall(SYS_futex,&inst->finished,FUTEX_WAIT|FUTEX_PRIVATE,1,0) != -ENOSYS
|| __syscall(SYS_futex,&inst->finished,FUTEX_WAIT,1,0);
return PTHREAD_BARRIER_SERIAL_THREAD;
}
//...
各所に工夫が散りばめられていて全部説明すると30分くらい説明が必要な気がしますが、細かい部分は省いてシーケンスの例を1つだけ示せば下記のようになります。
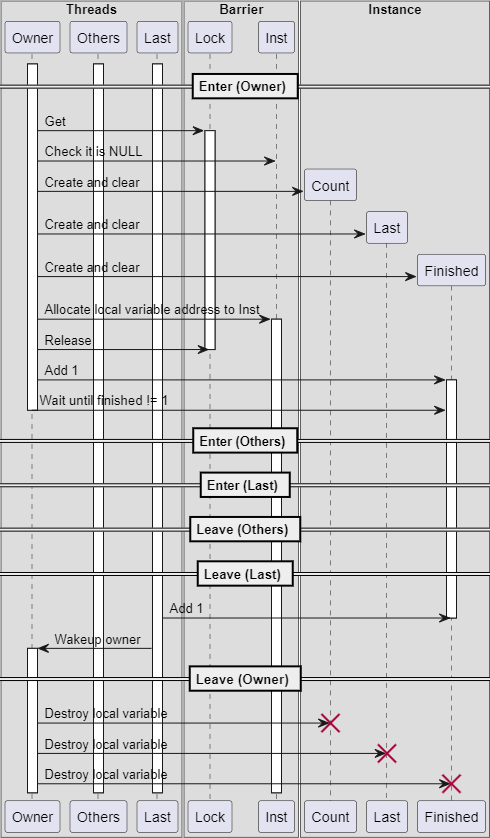
pthread_barrier_wait()のOwnerシーケンスの一例
特徴的というか個人的に感心した点は、インスタンスをローカル変数で確保していることです。変数のアドレスは一般的にはスレッドのスタック領域の一部になることが多いでしょう。ローカル変数の特徴として、
- 生存期間は関数実行している間だけ
- 他のスレッドと干渉しない
1つ目の特徴はmusl libcのバリア実装に限って言えば問題ありません。Ownerが必ず最後にバリア同期APIを脱出するように実装が工夫されていて、壊れたローカル変数に他のスレッドがアクセスする状況が発生しないからです。
2つ目の特徴はうまく活かしています。ローカル変数はバリアに一番最初にたどり着いたスレッド(= Owner)が、他スレッドと干渉せずインスタンスを確保できる簡単かつ高速な方法です。mallocのようなヒープでも目的は達成できますが、速度的に不利でしょう。面白い実装ですね。
続きはまた今度。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年11月29日
newlib-4.3.0 for RISC-V 32bitのバグ
RISC-V用のツールチェーンを更新しているときに気づいたバグです。
現在の時刻を取得するgettimeofday()というAPIがあります。newlib-4.1.0ではSYS_gettimeofdayを使っていましたが、newlib-4.3.0ではSYS_clock_gettime64を使うように変更されました。が、これがバグっていました。
newlib-4.3.0のgettimeofday()の実装
// newlib-cygwin/libgloss/riscv/sys_gettimeofday.c
/* Get the current time. Only relatively correct. */
int
_gettimeofday(struct timeval *tp, void *tzp)
{
#if __riscv_xlen == 32
struct __timespec64
{
int64_t tv_sec; /* Seconds */
# if BYTE_ORDER == BIG_ENDIAN
int32_t __padding; /* Padding */
int32_t tv_nsec; /* Nanoseconds */
# else
int32_t tv_nsec; /* Nanoseconds */
int32_t __padding; /* Padding */
# endif
};
struct __timespec64 ts64;
int rv;
rv = syscall_errno (SYS_clock_gettime64, 2, 0, (long)&ts64, 0, 0, 0, 0);
tp->tv_sec = ts64.tv_sec;
tp->tv_usec = ts64.tv_nsec * 1000; //★★計算式を間違えている、* 1000ではなく / 1000が正しい★★
return rv;
#else
return syscall_errno (SYS_gettimeofday, 1, tp, 0, 0, 0, 0, 0);
#endif
}
見ての通り、gettimeofdayは結果を秒(tv_sec)とマイクロ秒(tv_usec)のペアで返します。clock_gettime64は秒とナノ秒で結果を返してきますので、ナノ秒→マイクロ秒へ変換する必要があります。しかし悲しいことにナノ秒→マイクロ秒の変換コードがバグっており、マイクロ秒の値がかなり大きな値(本来1usなのに1msになってしまう(訂正: 1nsなのに1msになってしまう))になってしまいます。
長らく放置され、今日直っていた
実装変更がnewlibに入ったのは約2年前(2021年4月13日、commit id: 20d008199)でした。結構時間が経っていますね。先ほど紹介したgettimeofdayの実装はRISC-V 32bit向けの時しか使わないので、他のアーキを使っている開発者の皆様がバグに気づかなかったのだろうと思われます。
バグったコミット
commit 20d00819984058e439cfe40818f81d7315c89201
Author: Kito Cheng <kito.cheng@sifive.com>
Date: Tue Apr 13 17:33:03 2021 +0800
RISC-V: Using SYS_clock_gettime64 for rv32 libgloss.
- RISC-V 32 bits linux/glibc didn't provide gettimeofday anymore
after upstream, because RV32 didn't have backward compatible issue,
so RV32 only support 64 bits time related system call.
- So using clock_gettime64 call instead for rv32 libgloss.
このバグは既に下記のコミットで修正されています。
バグが修正されたコミット
commit 5f15d7c5817b07a6b18cbab17342c95cb7b42be4
Author: Kuan-Wei Chiu <visitorckw@gmail.com>
Date: Wed Nov 29 11:57:14 2023 +0800
RISC-V: Fix timeval conversion in _gettimeofday()
Replace multiplication with division for microseconds calculation from
nanoseconds in _gettimeofday function.
Signed-off-by: Kuan-Wei Chiu <visitorckw@gmail.com>
コミットの日付を見てびっくりしたのですが、なんと今日のコミットです。きっと世界のどこかで私と同じようなことを調べ、なんじゃこりゃー?!とバグを見つけて直した人が居たんでしょう。やー、奇遇ですね……。
コメント一覧
- 大山恵弘さん(2023/12/02 18:53)
すずきさんのX(旧Twitter)へのポストを見て気づいた可能性もあるかもしれないと思っています.
私はOSの時間管理に興味があるので時々gettimeofdayでエゴサーチをかけますが,そのエゴサーチで私はすずきさんのこのポストに気づきました.
そして,これはすごいバグがみつかったと思っていたところでした.
今回のfixを施したのは日本語を理解しない人かもしれませんが,当該ポストの画像を見れば何がまずいかはどの国の人にも一目瞭然だと思います.
- すずきさん(2023/12/03 00:35)
大山先生、お久しぶりです。コメントありがとうございます。
gettimeofdayでエゴサーチ……!!さすがです、私はやったことがありませんでした。
私がバグに気づいてnewlibのリポジトリをチェックしたとき、既に修正されていたので、本当にほぼ同時に気づいた(向こうの方が修正&ML投稿の時間分だけ早いですが)のだろうと思います。偶然ってすごいです。 - hdkさん(2023/12/03 18:49)
>(本来1usなのに1msになってしまう)
1 nsが1 msになる、ですかね。本来の値の範囲を大幅に超えて桁溢れもおこしてしまいそうなバグですね... - すずきさん(2023/12/04 00:38)
あ、そうか。1nsですね。ありがとうございます。
この記事にコメントする
2023年11月28日
glibcのclone_threadが使うシステムコール
目次: C言語とlibc
RISC-V向けglibcの実装を眺めていたところ、2.37と2.38でスレッドを作成する関数(__clone_internal関数)が使っているシステムコールが変わっていることに気づきました。
スレッドを作成するcloneシステムコールにはいくつか亜種がありますが、大抵のアーキテクチャではcloneとclone3が実装されています。cloneは引数を値で渡します。clone3は構造体へのポインタと構造体のサイズを渡します。cloneの引数は非常に多く、しかも昔より増えているような気がします……。今後の拡張も考えれば引数の個数に制限がある値渡しよりも、構造体のポインタを渡したほうが合理的ですね。
実装は全アーキテクチャ共通で、下記のような感じです。struct clone_argsがclone3に渡す構造体です。__clone3_internal()はcl_argsを直接clone3システムコールに渡します。__clone_internal_fallback()はcl_argsの各フィールドをバラバラにしてcloneシステムコールに渡します。
glibc-2.38のcloneの実装
// glibc/sysdeps/unix/sysv/linux/clone-internal.c
int
__clone_internal (struct clone_args *cl_args,
int (*func) (void *arg), void *arg)
{
#ifdef HAVE_CLONE3_WRAPPER
int saved_errno = errno;
int ret = __clone3_internal (cl_args, func, arg); //★★SYS_clone3を呼ぶ
if (ret != -1 || errno != ENOSYS)
return ret;
/* NB: Restore errno since errno may be checked against non-zero
return value. */
__set_errno (saved_errno);
#endif
return __clone_internal_fallback (cl_args, func, arg); //★★SYS_cloneを呼ぶ
}
これまで(2.37まで)のglibcのRISC-V向け実装でclone3システムコールが使われていなかった理由は、有効/無効のスイッチが無効側に設定されていたからです。スイッチとなるマクロ定義はsysdep.hというヘッダにあります。
clone3を使うか使わないかのスイッチ(RISC-V向け)
// glibc/sysdeps/unix/sysv/linux/riscv/sysdep.h
# define HAVE_CLONE3_WRAPPER 1
2.37まではHAVE_CLONE3_WRAPPERが未定義で、2.38ではHAVE_CLONE3_WRAPPERの定義が追加されました。以上が__clone_internal()が使っているシステムコールが変わる仕組みでした。良くできてます。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2023 | > | ||||
| << | < | 12 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | - | - | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 | - | - | - | - | - | - |
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
