 未来から過去へ表示(*)
未来から過去へ表示(*) 2025年2月19日
LinuxのI/O統計情報が読めないプロセスの謎を追う
目次: Linux
前回はsystemd --userの/proc/[pid]/ioが読めない件を紹介しました。今回はなぜ読めないのか、Linuxカーネルのコードを見て謎を追います。
アクセス違反判定されるまでのLinuxカーネルコード
// fs/proc/base.c
/*
* Thread groups
*/
static const struct pid_entry tgid_base_stuff[] = {
DIR("task", S_IRUGO|S_IXUGO, proc_task_inode_operations, proc_task_operations),
DIR("fd", S_IRUSR|S_IXUSR, proc_fd_inode_operations, proc_fd_operations),
//...
#ifdef CONFIG_TASK_IO_ACCOUNTING
ONE("io", S_IRUSR, proc_tgid_io_accounting), //★★★★
#endif
int proc_tgid_io_accounting(struct seq_file *m, struct pid_namespace *ns,
struct pid *pid, struct task_struct *task)
{
return do_io_accounting(task, m, 1); //★★★★
}
// fs/proc/base.c
#ifdef CONFIG_TASK_IO_ACCOUNTING
static int do_io_accounting(struct task_struct *task, struct seq_file *m, int whole)
{
struct task_io_accounting acct;
int result;
result = down_read_killable(&task->signal->exec_update_lock);
if (result)
return result;
if (!ptrace_may_access(task, PTRACE_MODE_READ_FSCREDS)) { //★★これ★★
result = -EACCES;
goto out_unlock;
}
if (whole) {
struct signal_struct *sig = task->signal;
struct task_struct *t;
unsigned int seq = 1;
unsigned long flags;
rcu_read_lock();
do {
seq++; /* 2 on the 1st/lockless path, otherwise odd */
flags = read_seqbegin_or_lock_irqsave(&sig->stats_lock, &seq);
acct = sig->ioac;
__for_each_thread(sig, t)
task_io_accounting_add(&acct, &t->ioac);
} while (need_seqretry(&sig->stats_lock, seq));
done_seqretry_irqrestore(&sig->stats_lock, seq, flags);
rcu_read_unlock();
} else {
acct = task->ioac;
}
seq_printf(m,
"rchar: %llu\n"
"wchar: %llu\n"
"syscr: %llu\n"
"syscw: %llu\n"
"read_bytes: %llu\n"
"write_bytes: %llu\n"
"cancelled_write_bytes: %llu\n",
(unsigned long long)acct.rchar,
(unsigned long long)acct.wchar,
(unsigned long long)acct.syscr,
(unsigned long long)acct.syscw,
(unsigned long long)acct.read_bytes,
(unsigned long long)acct.write_bytes,
(unsigned long long)acct.cancelled_write_bytes);
result = 0;
out_unlock:
up_read(&task->signal->exec_update_lock);
return result;
}
// kernel/ptrace.c
bool ptrace_may_access(struct task_struct *task, unsigned int mode)
{
int err;
task_lock(task);
err = __ptrace_may_access(task, mode); //★★これ★★
task_unlock(task);
return !err;
}
/* Returns 0 on success, -errno on denial. */
static int __ptrace_may_access(struct task_struct *task, unsigned int mode)
{
const struct cred *cred = current_cred(), *tcred;
struct mm_struct *mm;
kuid_t caller_uid;
kgid_t caller_gid;
if (!(mode & PTRACE_MODE_FSCREDS) == !(mode & PTRACE_MODE_REALCREDS)) {
WARN(1, "denying ptrace access check without PTRACE_MODE_*CREDS\n");
return -EPERM;
}
/* May we inspect the given task?
* This check is used both for attaching with ptrace
* and for allowing access to sensitive information in /proc.
*
* ptrace_attach denies several cases that /proc allows
* because setting up the necessary parent/child relationship
* or halting the specified task is impossible.
*/
/* Don't let security modules deny introspection */
if (same_thread_group(task, current))
return 0;
rcu_read_lock();
if (mode & PTRACE_MODE_FSCREDS) {
caller_uid = cred->fsuid;
caller_gid = cred->fsgid;
} else {
/*
* Using the euid would make more sense here, but something
* in userland might rely on the old behavior, and this
* shouldn't be a security problem since
* PTRACE_MODE_REALCREDS implies that the caller explicitly
* used a syscall that requests access to another process
* (and not a filesystem syscall to procfs).
*/
caller_uid = cred->uid;
caller_gid = cred->gid;
}
tcred = __task_cred(task);
if (uid_eq(caller_uid, tcred->euid) &&
uid_eq(caller_uid, tcred->suid) &&
uid_eq(caller_uid, tcred->uid) &&
gid_eq(caller_gid, tcred->egid) &&
gid_eq(caller_gid, tcred->sgid) &&
gid_eq(caller_gid, tcred->gid))
goto ok;
if (ptrace_has_cap(tcred->user_ns, mode))
goto ok;
rcu_read_unlock();
return -EPERM;
ok:
rcu_read_unlock();
/*
* If a task drops privileges and becomes nondumpable (through a syscall
* like setresuid()) while we are trying to access it, we must ensure
* that the dumpability is read after the credentials; otherwise,
* we may be able to attach to a task that we shouldn't be able to
* attach to (as if the task had dropped privileges without becoming
* nondumpable).
* Pairs with a write barrier in commit_creds().
*/
smp_rmb();
mm = task->mm;
if (mm &&
((get_dumpable(mm) != SUID_DUMP_USER) &&
!ptrace_has_cap(mm->user_ns, mode)))
return -EPERM;
return security_ptrace_access_check(task, mode); //★★これ★★
}
//security/security.c
int security_ptrace_access_check(struct task_struct *child, unsigned int mode)
{
return call_int_hook(ptrace_access_check, child, mode);
}
// include/linux/ptrace.h
//★★modeに指定されているPTRACE_MODE_READ_FSCREDS = MODE_READ | MODE_FSCREDSのこと
#define PTRACE_MODE_READ 0x01
#define PTRACE_MODE_ATTACH 0x02
#define PTRACE_MODE_NOAUDIT 0x04
#define PTRACE_MODE_FSCREDS 0x08
#define PTRACE_MODE_REALCREDS 0x10
/* shorthands for READ/ATTACH and FSCREDS/REALCREDS combinations */
#define PTRACE_MODE_READ_FSCREDS (PTRACE_MODE_READ | PTRACE_MODE_FSCREDS)
#define PTRACE_MODE_READ_REALCREDS (PTRACE_MODE_READ | PTRACE_MODE_REALCREDS)
#define PTRACE_MODE_ATTACH_FSCREDS (PTRACE_MODE_ATTACH | PTRACE_MODE_FSCREDS)
#define PTRACE_MODE_ATTACH_REALCREDS (PTRACE_MODE_ATTACH | PTRACE_MODE_REALCREDS)
まずはここまでです。それでも結構長いですね。呼び出しの順序はこんな感じです。
ここまでの呼び出し順序
proc_tid_io_accounting()
do_io_acconting()
ptrace_may_access()
security_ptrace_access_check()
call_int_hook(ptrace_access_check)
最後のcall_int_hook()の後はセキュリティ機能(SELinuxとか)の有無によって呼び出される関数が変わるようですが、一番大本のコンフィグCONFIG_SECURITYが有効になっていると、ケーパビリティのチェックが実行されます。
ケーパビリティチェック
// include/linux/capability.h
/*
* Check if "a" is a subset of "set".
* return true if ALL of the capabilities in "a" are also in "set"
* cap_issubset(0101, 1111) will return true
* return false if ANY of the capabilities in "a" are not in "set"
* cap_issubset(1111, 0101) will return false
*/
static inline bool cap_issubset(const kernel_cap_t a, const kernel_cap_t set)
return !(a.val & ~set.val);
// security/commoncap.c
int cap_ptrace_access_check(struct task_struct *child, unsigned int mode)
{
int ret = 0;
const struct cred *cred, *child_cred;
const kernel_cap_t *caller_caps;
rcu_read_lock();
cred = current_cred();
child_cred = __task_cred(child);
if (mode & PTRACE_MODE_FSCREDS)
caller_caps = &cred->cap_effective; //★こちらを通る★
else
caller_caps = &cred->cap_permitted;
if (cred->user_ns == child_cred->user_ns &&
cap_issubset(child_cred->cap_permitted, *caller_caps)) //★★★★この条件を満たさない
goto out;
if (ns_capable(child_cred->user_ns, CAP_SYS_PTRACE))
goto out;
ret = -EPERM; //★★★★EPERMエラーが返される
out:
rcu_read_unlock();
return ret;
}
相手側(child, systemd --userのプロセス)のeffectiveなケーパビリティが、自分側(child, ユーザーが起動したcatとか)のケーパビリティのサブセットかどうか?を見る部分でエラーになります。
ケーパビリティを確認
プロセスのケーパビリティを確認するには/proc/[pid]/statusを見ます。effectiveなケーパビリティはCapEffに表示されます。通常のプロセスは0ですが、systemd --userはCapEffに0ではない値が入っています。
systemd --userプロセスのケーパビリティ
$ cat /proc/1381/status | grep Cap CapInh: 0000000800000000 CapPrm: 0000000800000000 CapEff: 0000000800000000 CapBnd: 000001ffffffffff CapAmb: 0000000000000000
ケーパビリティを見やすく表示してくれるツールgetpcaps(Debianパッケージ名はlibcap2-bin)で見ると、
getpcapsでケーパビリティを表示
$ sudo getpcaps 1381 1381: cap_wake_alarm=eip
相手側のsystemd --userはcap_wake_alarmケーパビリティを持っていて、catなどは持っていません。従ってsystemd --userのケーパビリティはcatのケーパビリティのサブセット「ではない」です。先ほど紹介したコードにあったif文の条件を満たせずにEPERMが返されます。
コメント一覧
- katanaさん(2025/03/21 05:30)
katana
 この記事にコメントする
この記事にコメントする
2025年2月18日
LinuxのI/O統計情報が読めないプロセスが居る
目次: Linux
LinuxのI/O統計情報(/proc/[pid]/io)はユーザーが自分と一致するプロセスなら基本的に読めるはずですが、1つだけ読めない変なプロセスがいることに気づきました。
ユーザーが自分と一致するプロセスのI/O統計情報を読めるかチェック
$ LANG=C ls -l /proc/*/io | grep $USER | cut -d ' ' -f 9 | xargs cat > /dev/null
cat: /proc/1381/io: 許可がありません
cat: /proc/1744137/io: そのようなファイルやディレクトリはありません
cat: /proc/1744138/io: そのようなファイルやディレクトリはありません
cat: /proc/1744139/io: そのようなファイルやディレクトリはありません
$ ps 1381
PID TTY STAT TIME COMMAND
1381 ? Ss 0:00 /usr/lib/systemd/systemd --user
$ ps u 1381
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
katsuhi+ 1381 0.0 0.0 21512 11360 ? Ss 2024 0:00 /usr/lib/syst
$ /usr/lib/systemd/systemd --version
systemd 257 (257~rc3-1)
+PAM +AUDIT +SELINUX +APPARMOR +IMA +IPE +SMACK +SECCOMP +GCRYPT -GNUTLS +OPENSSL +ACL +BLKID +CURL +ELFUTILS +FIDO2 +IDN2 -IDN +IPTC +KMOD +LIBCRYPTSETUP +LIBCRYPTSETUP_PLUGINS +LIBFDISK +PCRE2 +PWQUALITY +P11KIT +QRENCODE +TPM2 +BZIP2 +LZ4 +XZ +ZLIB +ZSTD +BPF_FRAMEWORK +BTF -XKBCOMMON -UTMP +SYSVINIT +LIBARCHIVE
プロセスID 1744137〜1744139は、/proc/[pid]/ioの列挙に使ったls, grep, cutが、xargs catを実行するときに終了しているためで、気にしなくて良いはずです。しかしプロセスID 1381のsystemd --userは何かおかしいです。自分のプロセスのはずなのに読み出せなくてEPERMが返ります。
access()で調べる
不思議ですね。ファイルを読み出せるかどうかチェックするaccess()を使って調べましょう。
access()でファイルにアクセス可能かチェックするプログラム
#include <stdio.h>
#include <unistd.h>
void usage(int argc, char *argv[])
{
printf("usage:\n"
" %s filepath [filepath2 ...]\n", argv[0]);
}
const char *is_ok(int v)
{
if (v == 0) {
return "ok";
} else {
return "ng";
}
}
int main(int argc, char *argv[])
{
if (argc < 2) {
usage(argc, argv);
return 1;
}
for (int i = 1; i < argc; i++) {
const char *path = argv[i];
int fok, rok, wok, xok;
fok = access(path, F_OK);
rok = access(path, R_OK);
wok = access(path, W_OK);
xok = access(path, X_OK);
printf("%20s: f:%s r:%s w:%s x:%s\n",
path, is_ok(fok), is_ok(rok), is_ok(wok), is_ok(xok));
}
return 0;
}
access()でファイルにアクセス可能かチェックした結果
$ gcc -O2 main.c -o access_check
$ ./access_check /proc/1381/io
/proc/1381/io: f:ok r:ok w:ng x:ng
$ cat /proc/1381/io
cat: /proc/1381/io: 許可がありません
ファイルが存在し(f:ok)、読み出しが可能である(r:ok)と判定されますが、catで読もうとするとやはりEPERMが返されます。なんだこれは……?
コメント一覧
- コメントはありません。
この記事にコメントする
2025年2月17日
LinuxのI/O統計情報
目次: Linux
Linuxは各プロセスがどれくらいI/Oを行ったか記録していて、procファイルシステムの/proc/[pid]/ioファイルから読み出すことができます。
各フィールドの意味についてはUbuntuのマニュアル(Ubuntu Manpage: proc - プロセスの情報を含む疑似ファイルシステム)が日本語でも読めるしわかりやすいです。
I/O統計情報(/proc/[pid]/io)の例
(catを起動する、pidは1690787) $ cat /proc/1690787/io rchar: 3980 wchar: 0 syscr: 9 syscw: 0 read_bytes: 0 write_bytes: 0 cancelled_write_bytes: 0 (catにaとEnterを入力する) $ cat /proc/1690787/io rchar: 3982 wchar: 2 syscr: 10 syscw: 1 read_bytes: 0 write_bytes: 0 cancelled_write_bytes: 0
例としてaとEnterをcatに入力してみました。読み出し側を見てみると、rcharが2増えているのでaと改行文字の2バイトを、syscrが1増えているので1回のread()システムコールで読み出しているのでしょう。read_bytesが増えていないところを見ると、ファイルではなく端末から読み出したことも推測できます。
書き込み側はwcharが2増えているのでaと改行文字の2バイトを、syscwが1増えているので1回のwrite()システムコールで端末に書き出したと推測できます。読み込み側と異なり、書き込み側はファイルシステム層に書き出したかどうかは不明な仕様です。
I/O統計情報を有効にする方法
最近のUbuntuやDebianであればデフォルト有効ですが、わざと無効にしているシステムもあるので有効にする方法を紹介しておきます。
LinuxカーネルのCONFIG_TASK_IO_ACCOUNTINGを有効にすると使用できます。CONFIG_TASK_XACCT、CONFIG_TASKSTATSに依存しているので合わせて有効にする必要があります。menuconfigから有効にする場合は下記の場所にあります。
TASK_IO_ACCOUNTINGの設定位置
General setup --->
CPU/Task time and stats accounting --->
[*] Export task/process statistics through netlink
[*] Enable extended accounting over taskstats
[*] Enable per-task storage I/O accounting
ちなみにx86_64向けではデフォルトコンフィグarch/x86/configs/x86_64_defconfigで太古の昔、2008年くらい(2.6.30くらいの時代)から有効になっています。
コメント一覧
- コメントはありません。
この記事にコメントする
2025年2月10日
100万回のHello, World! - 補足
目次: ベンチマーク
前回はループ、再帰なし、1000バイト以下で100万回のHello, World!を実施する問題に対し、バイナリサイズを104バイトまで削るためのアイデアと実装方法をご紹介しました。
100万回のHello, World!プログラムの方は所定の範囲に収まって動作しているので、特に変えなくて良いです。気になるとすれば、プログラムの終了ステータスがエラー(今は60)になっている程度です。原因はexitシステムコールに渡す引数が0ではないからで、syscall命令を呼ぶ前にrdiを0にすれば直ります。まあ、できたら良いな程度で動作には関係ありません。
Linuxのシステムコール呼び出し規約は下記のようになっています。
| syscall num | return | arg1 | arg2 | arg3 | arg4 | arg5 | arg6 |
|---|---|---|---|---|---|---|---|
| rax | rax | rdi | rsi | rdx | r10 | r8 | r9 |
バイナリファイルのサイズをこれ以上短くしようとするなら、ELFヘッダとプログラムヘッダをさらに重ねる必要があります。ELFヘッダとプログラムヘッダを完全に重ねると64バイト(2020年7月5日の日記参照)になりますが、プログラムはSegmentation Faultになってしまって動作しませんから、動作可能な重ね方を探す必要があります。
コメント一覧
- hdkさん(2025/02/12 08:01)
なるほど、最後に%rdiを0にするのはこれでいけますね!
--ADDRS----F1---F2-
0000000A 01 3C
0000000B 58 6A
0000000C 89 01
0000000D C7 58
0000000E 90 50
00000028 90 5F
00000063 A5 A7
00000064 6A 58
00000065 3C 53
00000067 A3 A7
- hdkさん(2025/02/12 08:06)
あ、すみません、比較元に間違いがありました...
0000000F 68 BE
00000028 5E 5F
- すずきさん(2025/02/13 02:03)
解読しました。なるほど、exitの引数が0になっていい感じです〜。
_start:
mov %ebx, 1000000
push 0x3c
_loop:
push 0x1
pop %rax
push %rax
_last:
//mov esi,imm inst
.byte 0xbe
.word 0x0002
.word 0x003e
_second:
mov %dl, 0x0e
jmp _third
_third:
pop %rdi
add %esi, 0x46
syscall
jmp _fourth
_fourth:
dec %ebx
jne _loop
pop %rax
push %rbx
jmp _last
この記事にコメントする
2025年2月7日
100万回のHello, World! - バイナリサイズを削って遊ぼう、112バイトから104バイトへ
目次: ベンチマーク
前回はループ、再帰なし、1000バイト以下で100万回のHello, World!を実施する問題に対し、バイナリサイズを112バイトまで削るためのアイデアと実装方法をご紹介しました。今まで112バイトが限界だと思っていましたが、とあるサイト(Tiny ELF Files: Revisited in 2021)からいくつかヒントを得て104バイトにできました。
概要
サイズ104バイトの実行バイナリはこんな感じです。
100万回のHello, World!(104バイト版)
$ hexdump -C 104byte.out 00000000 7f 45 4c 46 bb 40 42 0f 00 6a 01 58 89 c7 90 68 |.ELF.@B..j.X...h| -> ELF header 00000010 02 00 3e 00 b2 0e eb 10 04 00 3e 00 00 00 00 00 |..>.......>.....| -> ELF header 00000020 30 00 00 00 00 00 00 00 5e 83 c6 46 0f 05 eb 30 |0.......^..F...0| -> ELF header 00000030 01 00 00 00 05 00 38 00 01 00 00 00 00 00 00 00 |......8.........| -> ELF, Program header 00000040 01 00 3e 00 00 00 00 00 48 65 6c 6c 6f 2c 20 57 |..>.....Hello, W| -> Program header 00000050 6f 72 6c 64 21 0a 00 00 6f 72 6c 64 21 0a 00 00 |orld!...orld!...| -> Program header 00000060 ff cb 75 a5 6a 3c eb a3 |..u.j<..| -> Program header 00000068 $ ./104byte.out | head Hello, World! Hello, World! Hello, World! Hello, World! Hello, World! Hello, World! Hello, World! Hello, World! Hello, World! Hello, World! $ ./104byte.out | wc 1000000 2000000 14000000
主な更新点は2つです。
- ELFヘッダとプログラムヘッダの重ねるサイズを8→16バイトに拡大
- p_vaddr == p_paddrは不要でp_addrは何でも良い
順番に説明したいと思います。
ELFヘッダとプログラムヘッダを重ねる
前回はELFヘッダとプログラムヘッダを8バイト重ねましたが、さらに+8バイトつまり16バイト重ねることができます。
| バイナリ位置 | ELFヘッダ | プログラムヘッダ |
|---|---|---|
| 0x30 | e_flags: 何でもOK | p_type: 0x0000_0001 |
| 0x34 | e_ehsize: 何でもOK | p_flags: 下位が0x0005(RX)、上位は何でもOK |
| 0x36 | e_phentsize: 0x0038 | |
| 0x38 | e_phnum: 0x0001 | p_offset_l: 0x0000_0001 |
| 0x3a | e_shentsize: 何でもOK | |
| 0x3c | e_shnum: 何でもOK | p_offset_h: 0x0000_0000 |
| 0x3e | e_shstrndx: 何でもOK |
今までp_type, p_flagsとe_flags〜e_phentsizeは重ねられないと思っていましたが、p_flagsは下位が0x0005(Read, Executable)であれば上位ワードは何でも良く、うまく重ねられることを知りました。いやーこれはすごい。この工夫によってELFヘッダ + プログラムヘッダのサイズが104バイトになります。
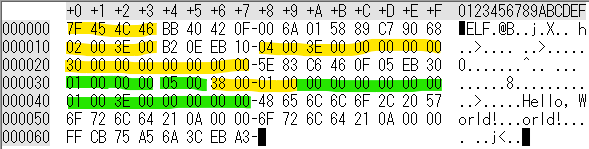
値を変更できない部分(黄色: ELFヘッダ由来、緑色: プログラムヘッダ由来)
今回のバイナリで自由に変更してはいけない部分に色を塗るとこんな感じです。黄色がELFヘッダに由来する制約、緑色がプログラムヘッダに由来する制約です。
ちなみにp_flagsにWriteをつけるとSEGVでクラッシュして、カーネルがこんなエラーログを出します。
p_flagsに0x7(RWX)を指定した時のカーネルのエラーログ
__vm_enough_memory: pid: 764111, comm: 104byte.out, bytes: 11138535030784 not enough memory for the allocation
Write属性をつけると書き込み用のメモリを確保しようとするのだと思われます。プログラムヘッダのp_fileszやp_memszにめちゃくちゃな値を指定しているため、そんなサイズは確保できずにエラーになります。従ってp_flagsは0x7(RWX)でなく0x5(RX)が必須です。
p_paddrは何でも良かった
プログラムヘッダのp_vaddr(オフセット0x40)とp_paddr(オフセット0x48)は同じ値でなければならないと勘違いしていましたが、実はp_paddrはどんな値でも動作することを知りました。ELFとプログラムヘッダの重ね合わせで失われた8バイトを挽回しうる空き地となるでしょう。
- e_identの先頭4バイトは0x7f, 'E', 'L', 'F
- e_type(オフセット0x10)は0x0002
- e_machine(オフセット0x12)は0x003e
- e_entry(オフセット0x18)は実行開始アドレス(エントリアドレス)を指す
- p_filesz == p_memszが必要
- p_fileszは何でもOKだが、大すぎる値はNG(上位2バイトは0じゃないとSegmentation Faultする)
ELFヘッダやプログラムヘッダの制約をリストアップするとこんなところです。
実装
前回はC言語の配列で作っていましたが、バイナリコードに変換するのが面倒くさいので最初からアセンブラで書きます。アセンブラ実装はトリッキー度合いが低い方(2024年2月26日の日記参照)を流用しました。
104バイト版の実装
.intel_syntax
.globl _start
.set _top, 0x3e0000
//e_ident
.byte 0x7f, 'E', 'L', 'F'
_start:
mov %ebx, 1000000
_loop:
push 0x01
_last:
pop %rax
mov %edi, %eax
nop
//push imm inst
.byte 0x68
//e_type
.word 0x0002
//e_machine
.word 0x003e
_second:
mov %dl, 0x0e
jmp _third
//e_entry
.quad _top + 4
//e_phoff
.quad 0x30
_third:
pop %rsi
add %esi, 0x46
syscall
jmp _fourth
//e_flags(any), p_type(0x01)
.long 0x01
//e_ehsize(any), p_flags low(0x05)
.word 0x05
//e_phentsize(0x38), p_flags high(any)
.word 0x38
//e_phnum(0x01), e_shentsize, e_shnum, e_shstrndx, p_offset(0x01)
.quad 0x01
//p_vaddr
.quad _top + 1
//p_paddr(any)
.byte 'H', 'e', 'l', 'l', 'o', ',', ' ', 'W'
//p_filesz
.byte 'o', 'r', 'l', 'd', '!', 0xa
.word 0
//p_memsz
.byte 'o', 'r', 'l', 'd', '!', 0xa
.word 0
//p_align(any)
_fourth:
dec %ebx
jne _loop
push 0x3c
jmp _last
トリッキーなことはせず素直に詰め替えましたが、それでも104バイトに収まりました。いいね〜。
ビルドと動作チェック方法
$ as 104byte.asm -o 104byte.o $ ld --oformat binary 104byte.o -o 104byte.out $ ./104byte.out | wc (略) $ ./104byte.out | head (略) $ objdump -D 104byte.o -M intel (Intel記法で逆アセンブルする方法です、デフォルトはAT&T記法)
ビルド方法はこんな感じです。
文字列アドレスのロードをバラバラにする
今回はHello, World!の出力にwriteシステムコールを使っていて、rsiレジスタに文字列の先頭アドレスを渡す必要があります。単純にmov命令でesiレジスタに32bit即値をセットすると、5バイト命令が必要で配置に大きな制約が生じますので、小さい命令に分割して配置を容易にする方法を考えます。
単純に分割するとpush 5バイト、pop 1バイト、add 3バイトですが、ELFヘッダ内で変更できない邪魔者であるe_typeとe_machineの前にバイト0x68を置いてpush 0x3e0002命令にしてしまえば、4バイト節約できます。pushした値は下位アドレス2なので文字列の先頭(0x3e0048)を指すため0x46をaddします。
e_typeとe_machineをpush命令にしている箇所
//push imm inst
.byte 0x68
//e_type
.word 0x0002
//e_machine
.word 0x003e
_second:
mov %dl, 0x0e
jmp _third
//e_entry
.quad _top + 4
//e_phoff
.quad 0x30
_third:
pop %rsi //pushした0x3e0002をpop
add %esi, 0x46 //esiの下位を0x02から0x48へ
syscall
jmp _forth
...
もう一つのカギはプログラムヘッダのp_vaddrを0x3e0001にして、プログラムを0x3e0001にロードすることです。下位バイトが1なのはプログラムヘッダのp_offsetが1になっているせいです。
コメント一覧
- hdkさん(2025/02/10 22:31)
push $0x3e0002のかわりにmov $0x3e0002,%esiにしてよくてそうするとpop %rsiをnopにできるんですが、空いたスペースの活用が難しく、push 0x3cをプログラム先頭に持っていってmov %eax,%ediをpush;popに分解すると、ふたつのnopのところにうまく埋まって2バイト縮むなぁと思ったら、実際に縮めたらエラーになって起動できませんでした。残念... - すずきさん(2025/02/12 00:11)
なるほど。動きそうなのになんで動かないんだろう……。
もっと短くできそうではあるんですけど、これ以上ELFヘッダとプログラムヘッダを重ねる方法が見つからない限りは、縮めてもnopが増えるだけでメリットがないんですよねえ。
この記事にコメントする
| < | 2025 | > | ||||
| << | < | 02 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | - | - | - | 1 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | - |
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
