2024年9月14日
OpenSBIを調べる - scratch領域の詳細
目次: Linux
今回はOpenSBIのコード内に頻出するscratch領域について調べます。OpenSBI内で設定値を格納するために何かと登場するscratch領域ですが、hartごとに用意されている領域であることくらいしか知りません。具体的にどこに配置されるのか?どんな領域があるのか?を調べます。
まずscratch領域の場所を調べましょう。アセンブラで書かれている_hartid_to_scratch()関数を読み解くのがわかりやすいでしょう。
scratch領域のアドレスを得るコード
// opensbi/lib/sbi/sbi_scratch.c
int sbi_scratch_init(struct sbi_scratch *scratch)
{
u32 i, h;
const struct sbi_platform *plat = sbi_platform_ptr(scratch);
for (i = 0; i < plat->hart_count; i++) {
h = (plat->hart_index2id) ? plat->hart_index2id[i] : i;
hartindex_to_hartid_table[i] = h;
//★★scratch領域の先頭アドレスはhartindex_to_scratch_table[]に保存されている★★
hartindex_to_scratch_table[i] =
((hartid2scratch)scratch->hartid_to_scratch)(h, i);
}
last_hartindex_having_scratch = plat->hart_count - 1;
return 0;
}
// opensbi/firmware/fw_base.S
.globl _hartid_to_scratch
_hartid_to_scratch:
/*
* a0 -> HART ID (passed by caller)
* a1 -> HART Index (passed by caller)
* t0 -> HART Stack Size
* t1 -> HART Stack End
* t2 -> Temporary
*/
lla t2, platform
#if __riscv_xlen > 32
lwu t0, SBI_PLATFORM_HART_STACK_SIZE_OFFSET(t2)
lwu t2, SBI_PLATFORM_HART_COUNT_OFFSET(t2)
#else
lw t0, SBI_PLATFORM_HART_STACK_SIZE_OFFSET(t2)
lw t2, SBI_PLATFORM_HART_COUNT_OFFSET(t2)
#endif
sub t2, t2, a1 /* hart数 - hart indexに */
mul t2, t2, t0 /* スタックサイズを掛ける */
/* index 0が末尾側、index 1が末尾の1つ手前となる */
lla t1, _fw_end /* OpenSBIバイナリの終端、メモリマップを参照 */
add t1, t1, t2 /* _fw_endの後ろがスタック領域 */
li t2, SBI_SCRATCH_SIZE /* 現状はSBI_SCRATCH_SIZE = 0x1000 */
sub a0, t1, t2 /* スタック領域の末尾がscratch領域 */
ret
コードを見る限り、scratch領域の場所を知るにはhartindexが必要です。hartindexはhartに関係する何かの配列のindexに使う値です。0〜hart数 - 1の値を取ります。
なぜhartidをindex代わりにしないのか?理由はRISC-Vのhartidがindex値として適していないからです。hartidは0から始まる連続した値とは限らず、非連続でも構いませんし、非常に大きな値をとっても構いません(推奨はされませんが)。そのためhartindexのような別概念を持ち出す必要があります。ちなみにhartindexとhartidの関係はhartindex_to_hartid_table[]に保持されています。
例えばhart数4、hartindex 0だとしますと、スタック領域はhart数分つまり4つあります。scratch領域の先頭は
(4 - 0) * hart_stack_size - SBI_SCRATCH_SIZE
なので、4つ目のスタック領域の末尾 - 0x1000です。図示したほうがわかりやすいでしょう。
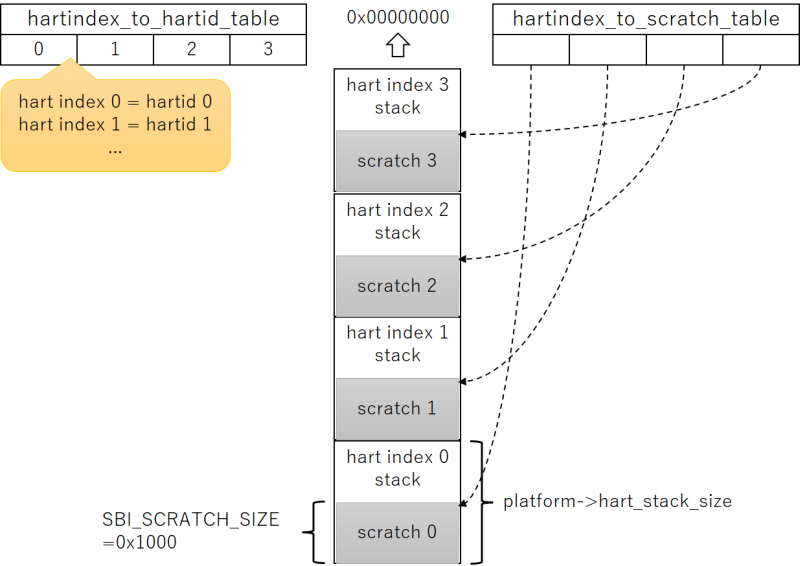
アドレスの高位側からhartindex 0, 1, 2, ...用のスタックおよびscratch領域が並んでいて、hartindex_to_hartid_table[]にhartindexとhartidの関係が保存されており、hartindex_to_scratch_table[]にhartindexとscratch領域の先頭アドレスの関係が保存されています。
scratch領域の中身
以上でscratch領域の場所はわかりました。次は領域の内部を調べましょう。コードを見るとscratch領域は2つの機能があります。
- 先頭にstruct sbi_scratchが存在
- 以降はsbi_scratch_alloc_offset()関数で確保するための領域
先頭に構造体があって、その後の領域はOpenSBI内で自由に確保して使う方式です。領域の確保にはsbi_scratch_alloc_offset()関数を使用します。コードはこんな感じ。
scratch領域にメモリを確保するコード
// opensbi/lib/sbi/sbi_scratch.c
unsigned long sbi_scratch_alloc_offset(unsigned long size)
{
u32 i;
void *ptr;
unsigned long ret = 0;
struct sbi_scratch *rscratch;
/*
* We have a simple brain-dead allocator which never expects
* anything to be free-ed hence it keeps incrementing the
* next allocation offset until it runs-out of space.
*
* In future, we will have more sophisticated allocator which
* will allow us to re-claim free-ed space.
*/
if (!size)
return 0;
size += __SIZEOF_POINTER__ - 1;
size &= ~((unsigned long)__SIZEOF_POINTER__ - 1);
spin_lock(&extra_lock);
if (SBI_SCRATCH_SIZE < (extra_offset + size))
goto done;
//★★extra_offsetは最初struct sbi_scratchの末尾を指している★★
//★★sbi_scratch_alloc_offset()が成功するたびに高位側のアドレスにズレていく★★
ret = extra_offset;
extra_offset += size;
done:
spin_unlock(&extra_lock);
if (ret) {
for (i = 0; i <= sbi_scratch_last_hartindex(); i++) {
rscratch = sbi_hartindex_to_scratch(i);
if (!rscratch)
continue;
ptr = sbi_scratch_offset_ptr(rscratch, ret);
sbi_memset(ptr, 0, size);
}
}
return ret;
}
柔軟で面白い仕組みですがscratch領域内に保存された情報がどこにあるか分かりづらく、コードを読む側としては嫌な作りとも言えます。下記の図にscratch領域にメモリを確保するとどうなるか?を示します。
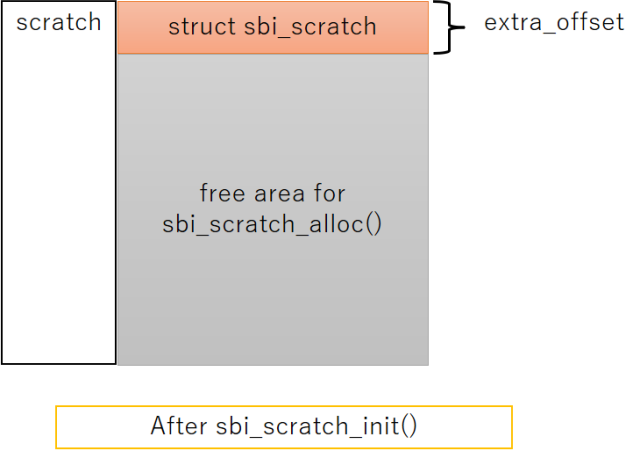
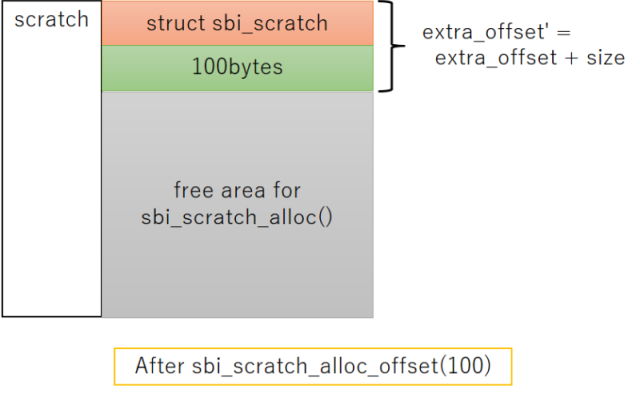
初期状態と100バイトのメモリ確保を行った後で、scratch領域のメモリマップとextra_offsetが高位側のアドレスにズレる様子を表しました。
scratch領域にメモリを確保する人たち
実際にはたくさんの領域が確保されます。下記はsbi_scratch_alloc_offset()を呼んでscratch領域にメモリを確保し、どんな種類のデータを何バイト確保しているか?の一覧表です。
| offsetを保存する変数名 | データ型 | サイズ |
|---|---|---|
| domain_hart_ptr_offset | pointer | 8 |
| entry_count_offset | pointer | 8 |
| init_count_offset | pointer | 8 |
| hart_data_offset | struct sbi_hsm_data | 56 |
| hart_features_offset | struct sbi_hart_features | 40 |
| fdt_isa_bitmap_offset | unsigned long[1] ※要素数=hart数 / 64 | 8 |
| shs_ptr_off | pointer | 8 |
| sse_inject_fifo_off | struct sbi_fifo | 24 |
| sse_inject_fifo_mem_off | struct sse_ipi_inject_data[5] | 20 |
| phs_ptr_offset | pointer | 8 |
| hart_state_ptr_offset | pointer | 8 |
| plic_ptr_offset | pointer | 8 |
| plic_mcontext_offset | long | 8 |
| plic_scontext_offset | long | 8 |
| ipi_data_off | struct sbi_ipi_data | 8 |
| mswi_ptr_offset | pointer | 8 |
| tlb_sync_off | atomic_t | 8 |
| tlb_fifo_off | struct sbi_fifo | 24 |
| tlb_fifo_mem_off | pointer | 8 |
| time_delta_off | u64 | 8 |
| mtimer_ptr_offset | pointer | 8 |
| fwft_ptr_offset | pointer | 8 |
表の1列目はsbi_scratch_alloc_offset()の返り値を保存している変数名です。hart_features_offsetを例にして、領域の確保を行っているコードと、領域のアドレスを取得するコードを見ましょう。
scratch領域の確保と参照をしているコードの例
// opensbi/lib/sbi/sbi_hart.c
int sbi_hart_init(struct sbi_scratch *scratch, bool cold_boot)
{
int rc;
/*
* Clear mip CSR before proceeding with init to avoid any spurious
* external interrupts in S-mode.
*/
csr_write(CSR_MIP, 0);
if (cold_boot) {
if (misa_extension('H'))
sbi_hart_expected_trap = &__sbi_expected_trap_hext;
//★★scratch領域に領域を確保する方法★★
//★★領域を確保して、scratch領域先頭からのオフセットアドレス(=返り値)を★★
//★★hart_features_offsetに保存★★
hart_features_offset = sbi_scratch_alloc_offset(
sizeof(struct sbi_hart_features));
if (!hart_features_offset)
return SBI_ENOMEM;
}
rc = hart_detect_features(scratch);
if (rc)
return rc;
return sbi_hart_reinit(scratch);
}
bool sbi_hart_has_extension(struct sbi_scratch *scratch,
enum sbi_hart_extensions ext)
{
//★★scratch領域に確保した領域を参照する方法★★
struct sbi_hart_features *hfeatures =
sbi_scratch_offset_ptr(scratch, hart_features_offset);
if (__test_bit(ext, hfeatures->extensions))
return true;
else
return false;
}
端的に言うと領域の確保にsbi_scratch_alloc_offset()関数、領域の参照にsbi_scratch_offset_ptr()関数を使えば良いです。
複数hartの場合は問題ない?
結論から言うと問題は起きません。領域確保時と領域参照時に分けて考えましょう。
最初にscratch領域のメモリを確保する場合です。これは単純で、初期化を担当する1つのhartだけがscratch領域のメモリ確保を行えば、同じ領域をダブって確保してしまう問題は発生しません。
次にscratch領域を参照する場合です。全てのhartが同じオフセットを使用すれば、重なったりはみ出たりする問題は発生しません。例えばsbi_scratch_alloc_offset()関数で確保したメモリ領域Aがありサイズ16、オフセット120だとしたら、全hartのscratch領域にメモリ領域Aが存在していて、同じサイズとオフセットであるとみなします。全hartのscratch領域の大きさが同じだからできる芸当ですね。
これで謎に包まれたOpenSBIのscratch領域も多少は晴れたはずです。たぶん……。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2024年9月13日
OpenSBIを調べる - OpenSBIとRISC-V ISA extensions
目次: Linux
今回はOpenSBIがRISC-Vの拡張機能をどのように認識し有効にするか調べます。
RISC-Vはたくさんの拡張命令と拡張機能が存在し、CPUやHWの実装によって対応する機能が異なります。そのためCPU/HWがRISC-Vのどの規格に対応しているのかを表す方法が必要です。RISC-Vの規格では命令セットと拡張機能をまとめて"rv64imafdc_aaa_bbb"のような文字列で表します。この文字列の名前がわからないのが困ったところですが、仕様書ではISA extensionsと書かれていることが多いようなので、以降はISA extensionsと表記します。
当初ISA extensionsは"rv64imafdc"のような「rv + ビット幅(32 or 64) + アルファベットの羅列(1文字=1つの拡張を表す)」だけの素朴なルールでしたが、際限なく増えるRISC-Vの拡張機能はこんなルールでは表せません。現在は"rv64imafdc_aaa_bbb_ccc"のようなアンダースコア + 拡張名を列車のように繋げるルール(RISC-V Unprivileged Architecture: Chapter 36. ISA Extension Naming Conventions)が採用されています。
例えばQEMUの仮想CPUのISA extensionsを見ると、
QEMUの仮想CPUのISA extensions
rv64imafdch_zic64b_zicbom_zicbop_zicboz_ ziccamoa_ziccif_zicclsm_ziccrse_ zicntr_zicsr_zifencei_zihintntl_ ihintpause_zihpm_za64rs_zawrs_ zfa_zca_zcd_zba_ zbb_zbc_zbs_ssccptr_ sscounterenw_sstc_sstvala_sstvecd_ svadu
本来はとても長い1行ですが、見づらいため4つごとに改行を入れています。もはやISA extensionsは魔法の呪文か暗号の様相を呈していて、どこか一文字だけ間違えていたとしても気付ける自信がありません。
OpenSBIが拡張機能を認識する方法
拡張機能の認識方法を調べます。答えを先に書くとデバイスツリーのcpuノードのriscv,isaプロパティの長い長い文字列を頭から解析しています。割と力技でした。
デバイスツリーのCPUノード、riscv,isaプロパティの例
/ {
cpus {
cpu0: cpu@0 {
device_type = "cpu";
reg = <0>;
compatible = "riscv";
riscv,isa-base = "rv64i";
riscv,isa = "rv64imafdc_zicsr_zifencei_zba_zbb_zbs"; //★★これ★★
status = "okay";
//...
ISA extensionsの文字列解析をする関数はfdt_parse_isa_one_hart()関数です。
fdt_parse_isa_one_hart()関数の呼び出し履歴
sbi_init @ lib/sbi/sbi_init.c
init_coldboot @ lib/sbi/sbi_init.c
sbi_hart_init @ lib/sbi/sbi_hart.c
hart_detect_features @ lib/sbi/sbi_hart.c
sbi_platform_extensions_init @ include/sbi/sbi_platform.h
sbi_platform_ops(plat)->extensions_init(hfeatures);
-> generic_extensions_init @ platform/generic/platform.c
fdt_parse_isa_extensions @ lib/utils/fdt/fdt_helper.c
fdt_parse_isa_all_harts @ lib/utils/fdt/fdt_helper.c
fdt_parse_isa_one_hart @ lib/utils/fdt/fdt_helper.c
GenericプラットフォームをQEMU用のデバイスツリーで動作させた際の呼び出し経路はこんな感じです。3つ上位のfdt_parse_isa_all_harts()関数を見ると、
ISA extensionsを解析する処理と結果を格納する部分のコード
// opensbi/platform/generic/platform.c
static int generic_extensions_init(struct sbi_hart_features *hfeatures)
{
int rc;
//★★第3引数hfeatures->extensionsにISA extensionsの解析結果を書き込む★★
//★★hfeaturesはscratch領域のhart_features_offsetバイト目、手元の環境だと192バイト目★★
/* Parse the ISA string from FDT and enable the listed extensions */
rc = fdt_parse_isa_extensions(fdt_get_address(), current_hartid(),
hfeatures->extensions);
if (rc)
return rc;
if (generic_plat && generic_plat->extensions_init)
return generic_plat->extensions_init(generic_plat_match,
hfeatures);
return 0;
}
// opensbi/lib/utils/fdt/fdt_helper.c
int fdt_parse_isa_extensions(void *fdt, unsigned int hartid,
unsigned long *extensions)
{
int rc, i;
unsigned long *hart_exts;
struct sbi_scratch *scratch;
if (!fdt_isa_bitmap_offset) {
fdt_isa_bitmap_offset = sbi_scratch_alloc_offset(
sizeof(*hart_exts) *
BITS_TO_LONGS(SBI_HART_EXT_MAX));
if (!fdt_isa_bitmap_offset)
return SBI_ENOMEM;
//★★この関数がISA extensionsの解析結果を置く場所は★★
//★★scratch領域 + fdt_isa_bitmap_offsetの場所★★
rc = fdt_parse_isa_all_harts(fdt);
if (rc)
return rc;
}
scratch = sbi_hartid_to_scratch(hartid);
if (!scratch)
return SBI_ENOENT;
//★★scratch領域 + fdt_isa_bitmap_offsetの場所を取得する★★
hart_exts = sbi_scratch_offset_ptr(scratch, fdt_isa_bitmap_offset);
//★★ISA extensionsの解析結果は、hfeatures->extensionsに全てまとめられる★★
for (i = 0; i < BITS_TO_LONGS(SBI_HART_EXT_MAX); i++)
extensions[i] |= hart_exts[i];
return 0;
}
// opensbi/lib/utils/fdt/fdt_helper.c
static int fdt_parse_isa_all_harts(void *fdt)
{
u32 hartid;
const fdt32_t *val;
unsigned long *hart_exts;
struct sbi_scratch *scratch;
int err, cpu_offset, cpus_offset, len;
if (!fdt || !fdt_isa_bitmap_offset)
return SBI_EINVAL;
cpus_offset = fdt_path_offset(fdt, "/cpus");
if (cpus_offset < 0)
return cpus_offset;
fdt_for_each_subnode(cpu_offset, fdt, cpus_offset) {
err = fdt_parse_hart_id(fdt, cpu_offset, &hartid);
if (err)
continue;
if (!fdt_node_is_enabled(fdt, cpu_offset))
continue;
//★★device treeのriscv,isaプロパティを見る★★
val = fdt_getprop(fdt, cpu_offset, "riscv,isa", &len);
if (!val || len <= 0)
return SBI_ENOENT;
scratch = sbi_hartid_to_scratch(hartid);
if (!scratch)
return SBI_ENOENT;
//★★解析結果を置く場所はscratch領域 + fdt_isa_bitmap_offsetの場所★★
hart_exts = sbi_scratch_offset_ptr(scratch,
fdt_isa_bitmap_offset);
//★★riscv64imafdc_zicsr_zifencei_...のような文字列を解析する★★
err = fdt_parse_isa_one_hart((const char *)val, hart_exts);
if (err)
return err;
}
return 0;
}
デバイスツリーのcpusノードを探して、子ノード(cpu@0など)のriscv,isaプロパティを読み出して、文字列解析するfdt_parse_isa_one_hart()関数に渡していることがわかります。
解析結果はscratch領域(OpenSBIのhartごとの情報を保持しておくメモリ領域、スタック領域の末尾に確保される)のfdt_isa_bitmap_offsetに置かれ、最終的には別のscratch領域にあるfeatures->extensionsにまとめられます。scratch領域の詳細が気になるところですが、また別の機会に調べることにします。
OpenSBIが拡張機能を有効にする方法
拡張機能はリセット直後は無効になっているものもあるので、有効にする必要があります。RISC-V Privileged Architectureではmenvcfgレジスタがあり、適切なビットフィールドに値をセットして機能の有効/無効を切り替える場合があります。有効/無効が設定できない機能もあって、統一感がないです……。
例えばS-mode用のタイマーコンペアレジスタ(stimecmpレジスタ)を定義しているSSTC拡張では、menvcfgのビット63 STCE(STimecmp Enable)フィールドに1をセットすると機能が有効になります。機能を有効にせずstimecmpにアクセスするとillegal instruction例外が発生します。
OpenSBIのコードでmenvcfgレジスタに値を設定する関数は下記のmstatus_init()です。
拡張機能を有効にするためmenvcfgレジスタに値を設定するコード
// opensbi/lib/sbi/sbi_hart.c
/**
* Check whether a particular hart extension is available
*
* @param scratch pointer to the HART scratch space
* @param ext the extension number to check
* @returns true (available) or false (not available)
*/
bool sbi_hart_has_extension(struct sbi_scratch *scratch,
enum sbi_hart_extensions ext)
{
struct sbi_hart_features *hfeatures =
sbi_scratch_offset_ptr(scratch, hart_features_offset);
if (__test_bit(ext, hfeatures->extensions))
return true;
else
return false;
}
static void mstatus_init(struct sbi_scratch *scratch)
{
int cidx;
unsigned long mstatus_val = 0;
unsigned int mhpm_mask = sbi_hart_mhpm_mask(scratch);
uint64_t mhpmevent_init_val = 0;
uint64_t menvcfg_val, mstateen_val;
//...
if (sbi_hart_priv_version(scratch) >= SBI_HART_PRIV_VER_1_12) {
menvcfg_val = csr_read(CSR_MENVCFG);
#if __riscv_xlen == 32
menvcfg_val |= ((uint64_t)csr_read(CSR_MENVCFGH)) << 32;
#endif
#define __set_menvcfg_ext(__ext, __bits) \
if (sbi_hart_has_extension(scratch, __ext)) \
menvcfg_val |= __bits;
/*
* Enable access to extensions if they are present in the
* hardware or in the device tree.
*/
//★★sbi_hart_has_extension()関数で拡張機能の一覧hfeatures->extensionsのビットをテストする★★
//★★拡張機能が存在しているなら、menvcfgの相当するビットをセットする★★
__set_menvcfg_ext(SBI_HART_EXT_ZICBOZ, ENVCFG_CBZE)
__set_menvcfg_ext(SBI_HART_EXT_ZICBOM, ENVCFG_CBCFE)
__set_menvcfg_ext(SBI_HART_EXT_ZICBOM,
ENVCFG_CBIE_INV << ENVCFG_CBIE_SHIFT)
#if __riscv_xlen > 32
__set_menvcfg_ext(SBI_HART_EXT_SVPBMT, ENVCFG_PBMTE)
#endif
__set_menvcfg_ext(SBI_HART_EXT_SSTC, ENVCFG_STCE)
__set_menvcfg_ext(SBI_HART_EXT_SMCDELEG, ENVCFG_CDE);
__set_menvcfg_ext(SBI_HART_EXT_SVADU, ENVCFG_ADUE);
#undef __set_menvcfg_ext
/*
* When both Svade and Svadu are present in DT, the default scheme for managing
* the PTE A/D bits should use Svade. Check Svadu before Svade extension to ensure
* that the ADUE bit is cleared when the Svade support are specified.
*/
if (sbi_hart_has_extension(scratch, SBI_HART_EXT_SVADE))
menvcfg_val &= ~ENVCFG_ADUE;
csr_write(CSR_MENVCFG, menvcfg_val); //★★menvcfgを設定、拡張機能が有効になる★★
#if __riscv_xlen == 32
csr_write(CSR_MENVCFGH, menvcfg_val >> 32);
#endif
/* Enable S-mode access to seed CSR */
if (sbi_hart_has_extension(scratch, SBI_HART_EXT_ZKR)) {
csr_set(CSR_MSECCFG, MSECCFG_SSEED);
csr_clear(CSR_MSECCFG, MSECCFG_USEED);
}
}
/* Disable all interrupts */
csr_write(CSR_MIE, 0);
/* Disable S-mode paging */
if (misa_extension('S'))
csr_write(CSR_SATP, 0);
}
以上がOpenSBIによって拡張機能が認識&有効になる仕掛けです。ISA extensionsを間違えるとこの仕組みは動かないので、ISA extensionsの長くて難しくて間違いやすい記述はどうすれば良いの?と疑問が湧きます。しかしその答えはOpenSBIにはなさそうですね……。
ちなみにmenvcfgの詳細はPrivileged Architecture(GitHubにソースコードがあります、PDFはReleasesからダウンロード可能)に記載されています。なんちゃら拡張が使う予定のビットフィールドなのでそちらを参照せよと書いていることも多く、各々の拡張機能の仕様書を行脚することになるでしょう。
コメント一覧
- コメントはありません。
この記事にコメントする
2024年9月9日
GDBの便利コマンド
目次: Linux
GDBは便利ですが、少し使わないでいるとあっという間にコマンドを忘れます。便利&使うコマンドをメモしておきます。
handle - シグナルの扱いを変更する
GDBはデバッグ中のプログラムがシグナルを受け取ると実行停止してどうするか聞いてきます。この機能は便利ですが、シグナルをプロセス間で送りあって動くようなプログラムだと頻繁に停止して鬱陶しいです。
handleコマンドでSIGUSR1を非停止、非表示、対象に渡す設定にする
(gdb) handle SIGUSR1 nostop noprint Signal Stop Print Pass to program Description SIGUSR1 No No Yes User defined signal 1
こんなときはhandleコマンドで無視したり非表示にできます。私はあまり使ったことがないのですが、nopassにするとシグナルをデバッグ対象に渡さないようにできるようです。
dump - メモリの内容をファイルにセーブ
指定したメモリの内容をファイルにコピーします。個人的には間違えやすいコマンドで、3番目の引数のmemoryをいつも打ち忘れます。
0x80000000のメモリをfoo.binにセーブ
(gdb) dump binary memory foo.bin 0x80000000 0x80001000
意外と長くなります。
restore - ファイルの内容をメモリにロード
指定したファイルの内容をメモリにコピーします。個人的には名前間違え率No.1なコマンドで、loadコマンドと間違えます。
foo.binを0x80000000にロード
(gdb) restore foo.bin binary 0x80000000
なんでloadじゃないんだよ?と思いますが、loadは別の意味のコマンド(デバッグ対象プログラムをメモリにロードする、ただコピーするだけではなくプログラムヘッダを考慮する)に使われているためです。
symbol-file - デバッグシンボルをロード
実行可能ファイルからデバッグシンボルを読み出すコマンドです。-oオプションにより、シンボルのアドレスにオフセットを加えることもできます。
foo.elfのシンボルアドレスに0x80000000オフセットをかけてロード
(gdb) symbol-file foo.elf -o 0x80000000
通常のデバッグではGDBが実行ファイルをロードするのであまりお世話になりませんが、組み込み開発では割とお世話になるコマンドです。ROM上に既にロード済みのバイナリのデバッグシンボルを後から読みたいとき、PIEのプログラム(アドレスが0スタートになっている)をデバッグするときに便利です。
コメント一覧
- コメントはありません。
この記事にコメントする
2024年9月6日
ベレッタ92が壊れた
目次: 射的
ガスガンのベレッタ92(正確な商品名は東京マルイ U.S. M9ピストル)が壊れました。デコッキングすると100%暴発します。怖い故障モードですね……。それはさておいて週1回の使用とはいえ、2年半も使えたのは割と良い方なんですかね?
初めはスライド側セーフティー周りの故障かと思いましが、どうやらフレーム側のデコッキング機構がダメになったようです。ほぼ新品のM9A1(※)のスライドと載せ替えても暴発しています。これはもうダメそうだなー……。
修理も考えましたがやめました。私は特に改造せずほぼノーマルのまま使っているので、新しい銃に入れ替えても特に問題ないのです。てな訳で、新しくもう1丁購入しました。
(※)東京マルイM9A1のこと(M9A1の製品リンク)です。M9A1もベレッタ92ベースの銃で、スライドはU.S. M9ピストルと機構的に互換性があります。スライドを入れ替えても正常に動作します。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2024 | > | ||||
| << | < | 09 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | - | - | - | - | - |
最近のコメント5件
最近の記事20件
-
 23年5月15日
23年5月15日
すずき (07/22 03:04)
「[車 - まとめリンク] 目次: 車三菱 FTO GPX '95の話。群馬県へのドライブ1群馬県へのドライブ2将来車を買い替え...」 -
26年7月22日
すずき (07/22 03:04)
「[ジャガーさんの冷却水漏れの修理見積もり] 目次: 車先週、冷却水がほぼなくなってしまい修理工場にレッカーしたジャガーさんです...」 -
26年7月14日
すずき (07/22 02:37)
「[ジャガーさんの冷却水漏れ] 目次: 車朝、出勤しようと思ってエンジンをかけたところ冷却水不足と表示されました。わぁ、ついに出...」 -
26年7月19日
すずき (07/20 04:04)
「[ゲームを買ったら遊びましょう4] 目次: ゲーム前回の振り返り(2025年12月22日の日記参照)から半年経ちました。Swi...」 -
21年12月28日
すずき (07/20 04:03)
「[ゲーム - まとめリンク] 目次: ゲームNintendo DSを買ったパネルでポンDS最近の朝はパネポンDS聖剣伝説DSチ...」 -
26年7月13日
すずき (07/19 23:33)
「[Flightradar24のcontributorになる方法] 目次: 自宅サーバーADS-Bを受信できる環境があればFli...」 -
23年6月1日
すずき (07/19 23:31)
「[自宅サーバー - まとめリンク] 目次: 自宅サーバーこの日記システム、Wikiの話。カウンターをPerlからPHPに移植日...」 -
23年9月11日
すずき (07/15 12:18)
「[Windows - まとめリンク] 目次: WindowsWindows XPのブリッジ機能colinuxとWindowsの...」 -
25年1月31日
すずき (07/15 12:18)
「[Windowsの日本語フォントはみな長生き] 目次: WindowsGNOME48からフォントが変わるニュースを見ていて、フ...」 -
26年7月11日
すずき (07/12 01:26)
「[Timberborn、トロフィーコンプ] 目次: ゲームTimberbornのトロフィーをコンプリートしました。アーリーアク...」 -
24年2月7日
すずき (07/11 13:05)
「[複数の音声ファイルのラウドネスを統一したい] 目次: PythonPCやデジタル音楽プレーヤーで音楽を聞いていると、曲によっ...」 -
26年6月27日
すずき (07/08 01:45)
「[ジャガーさんのバンパー修理] 目次: 車以前(2025年11月21日の日記参照)、ジャガーさんの左前をぶつけてバンパーをガリ...」 -
26年7月3日
すずき (07/08 00:42)
「[ADS-Bを受信して飛行機の位置を見よう] 目次: 自宅サーバー空を飛ぶ飛行機は離陸直後や着陸寸前でもない限り飛んでいる姿は...」 -
26年7月1日
すずき (07/04 02:37)
「[GPSは世界一正確な時計、その3 - ntpsecとgpsd] 目次: 自宅サーバー以前(2015年5月8日の日記参照)、G...」 -
26年6月26日
すずき (07/03 05:23)
「[ジャガーさんの不思議なシフト] 目次: 車ジャガーXE(前期型)はシフトがダイヤル型になっていて、P, R, N, D, S...」 -
20年2月22日
すずき (06/26 02:03)
「[Zephyr - まとめリンク] 目次: Zephyr導入、ブート周りHello! Zephyr OS!!Hello! Ze...」 -
26年6月18日
すずき (06/26 02:02)
「[ZephyrのOut-of-treeアプリケーションその6 - シリアル出力] 目次: Zephyr前回はシリアルに文字を出...」 -
26年6月23日
すずき (06/26 01:27)
「[ANA国内線予約サイトが悲惨なことに] 4月くらいにANAの国内線予約サイトが国際線と共通のクラウドシステム(Amadeus...」 -
26年6月11日
すずき (06/26 01:10)
「[ZephyrのOut-of-treeアプリケーションその5 - OpenOCDとGDBで実行] 目次: Zephyr前回Ze...」 -
26年4月29日
すずき (06/24 01:10)
「[ぽこあポケモンをクリア] 目次: ゲーム1日だけやって放置していたぽこあポケモンをクリア(=スタッフロールが流れるイベントを...」
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
